Welcome
Welcome to the Course Website for EN.580.428 Genomic Data Visualization!
As the primary mode through which analysts and audience members alike consume data, data visualization remains an important hypothesis generating and analytical technique in data-driven research to facilitate new discoveries. However, if done poorly, data visualization can also mislead, bias, and slow down progress. This hands-on course will cover the principles of perception and cognition relevant for data visualization and apply these principles to genomic data, including large-scale spatially-resolved omics datasets, using the R statistical programming language. Students will be expected to complete class readings, create weekly data visualizations as homework assignments, and make a major class presentation.
Course Information
Course Staff: Prof. Jean Fan and Suki
Lectures: 8:00am-9:50am Monday, Wednesday, and Friday. See Canvas for location details.
Office Hours: 10:00am-10:50am Monday, Wednesday, and by request. See Canvas for location details.
Course Details
☞ see Course tabFeatured Visualizations
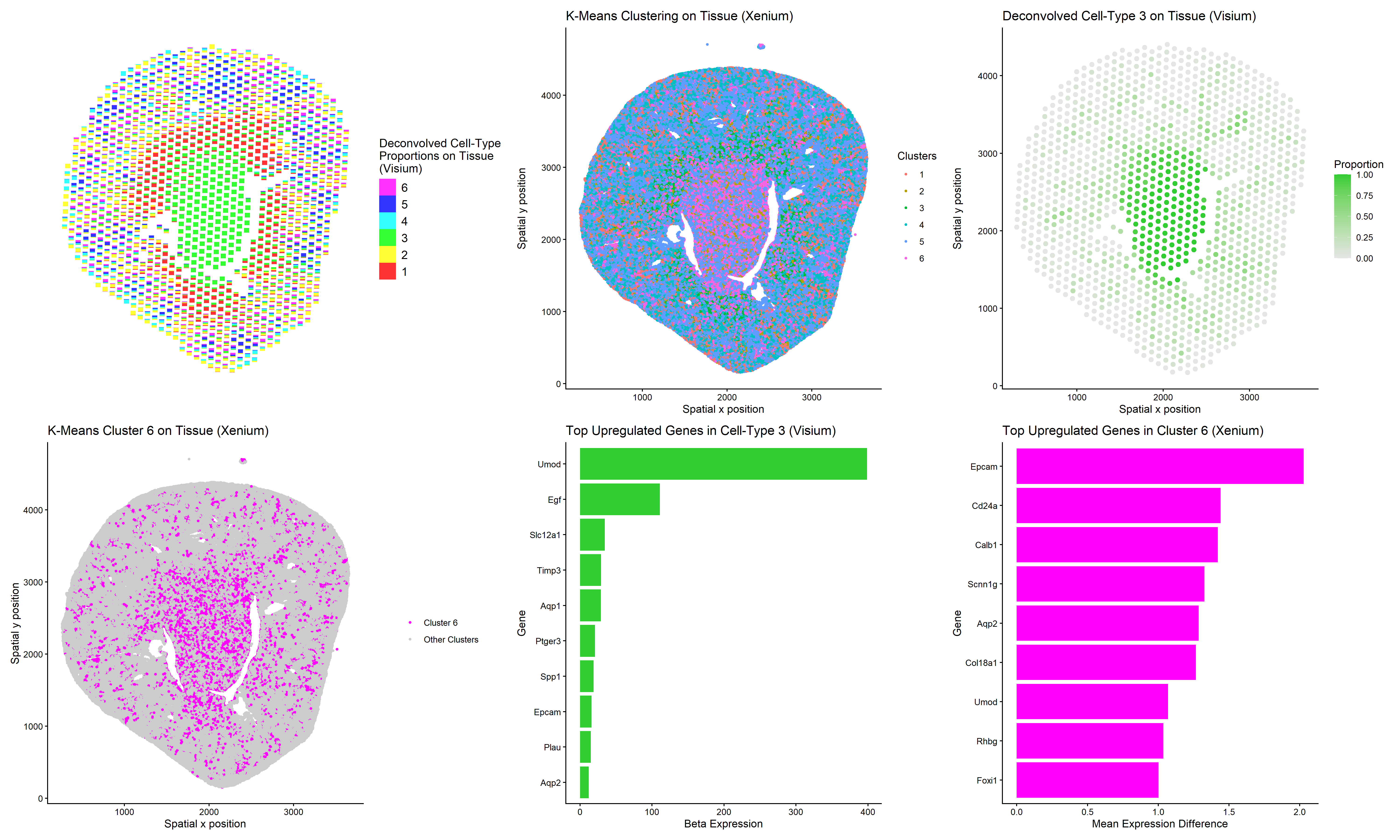
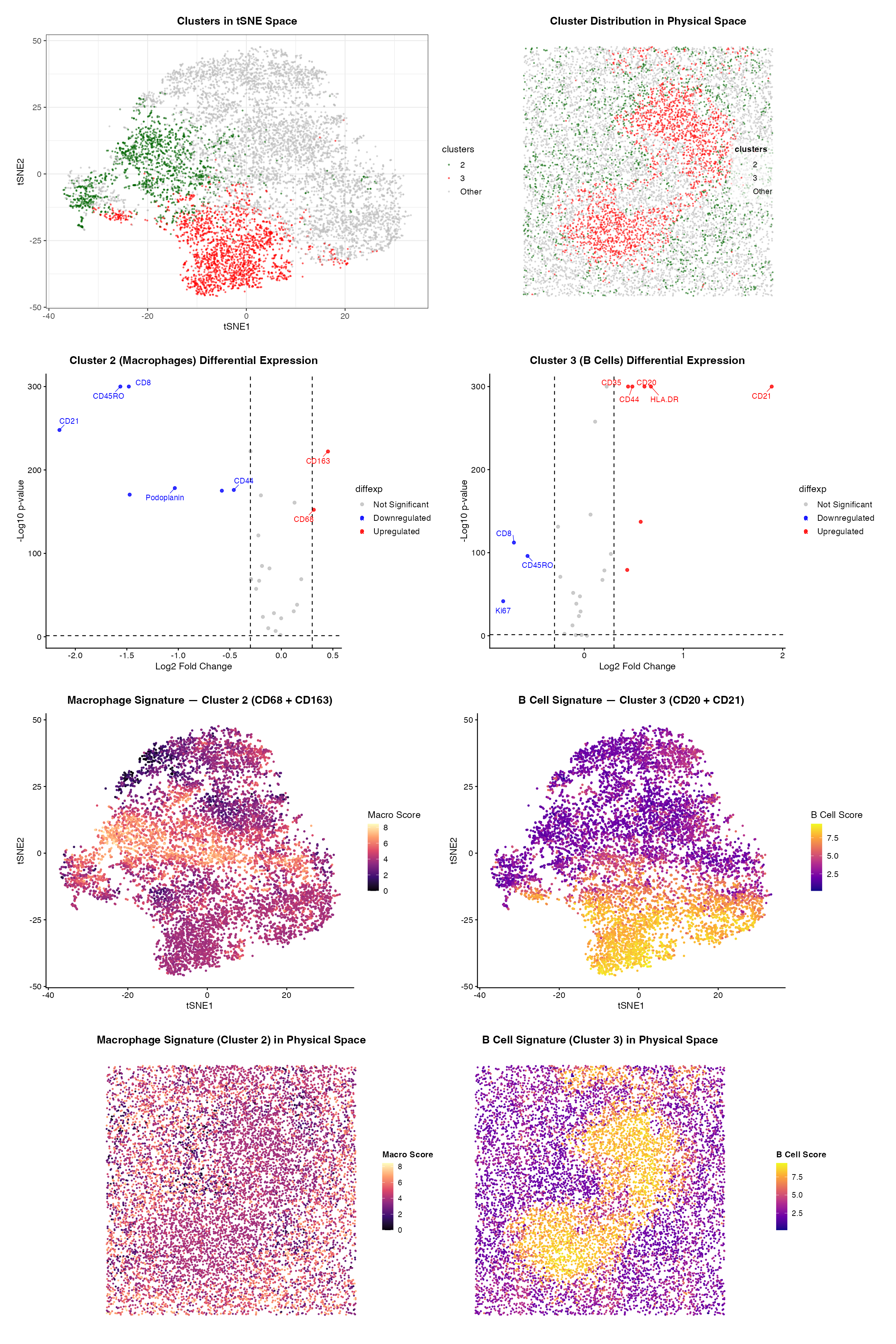
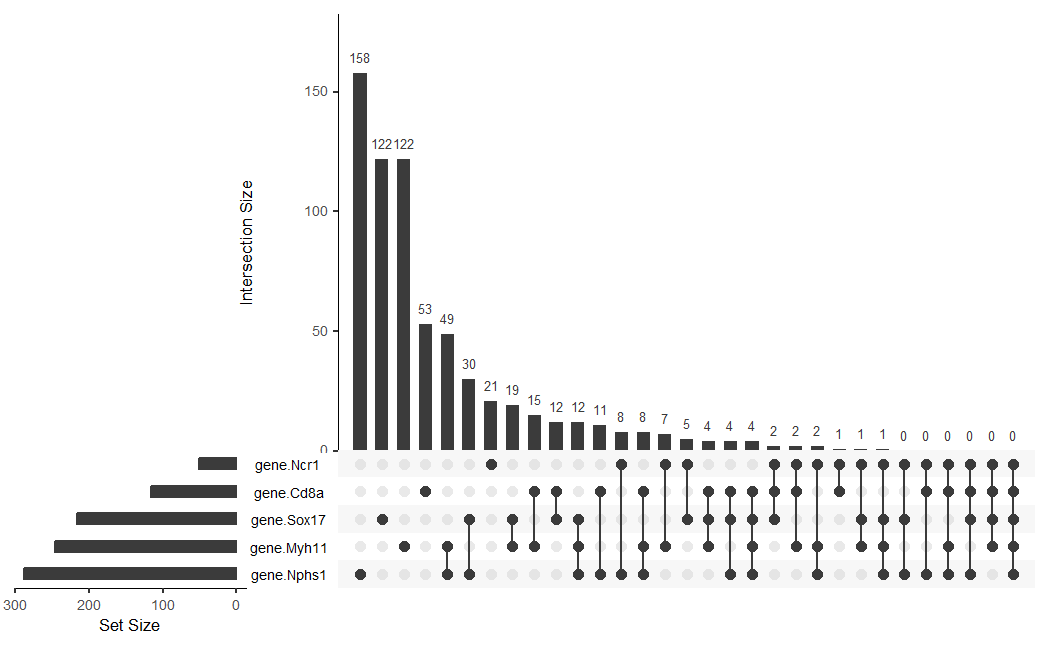
Using clustering and deconvolution to visualize cell types and upregulated genes in different data sets
1. Figure description This multi-panel data visualization uses principal component analysis (PCA), t-distributed stochastic neighbor embedding (tSNE), k-means clustering, deconvolution, and differential expression analysis to...

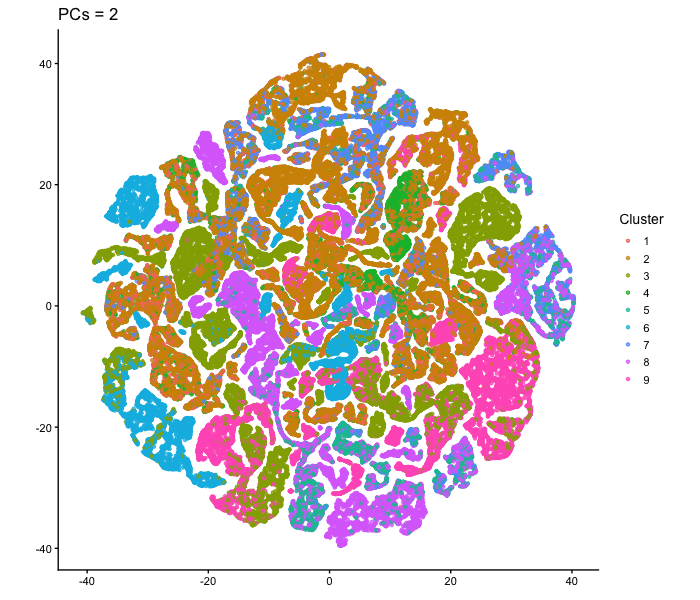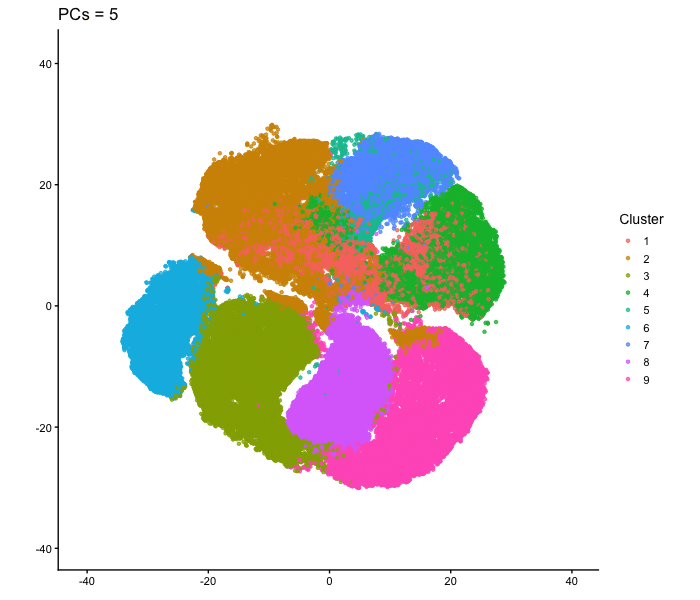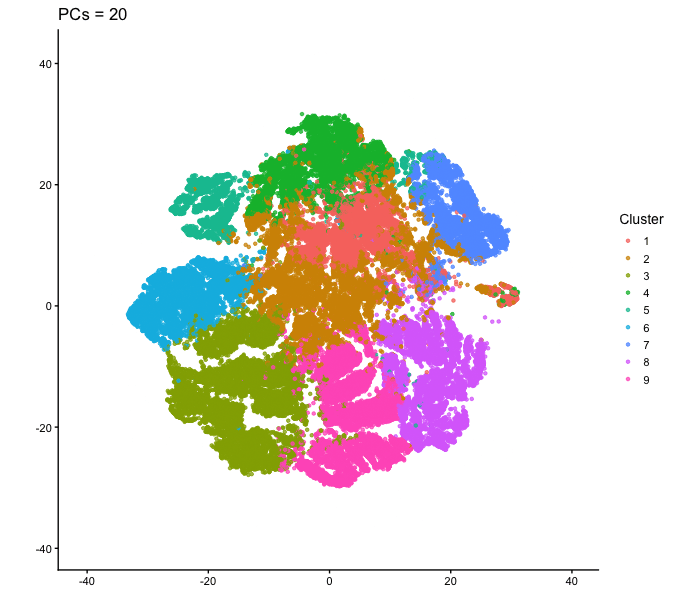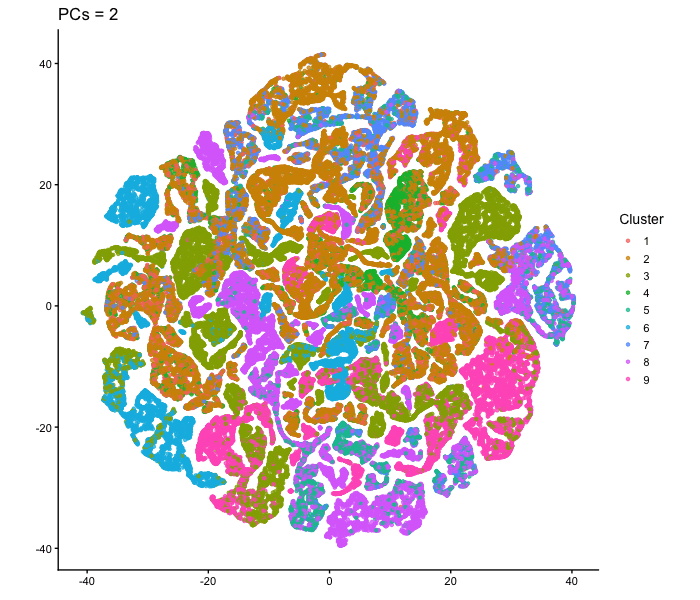
tSNE on varying PC numbers
Description This animation adresses the question: “If I perform non-linear dimensionality reduction on PCs, what happens when I vary how many PCs I use?”

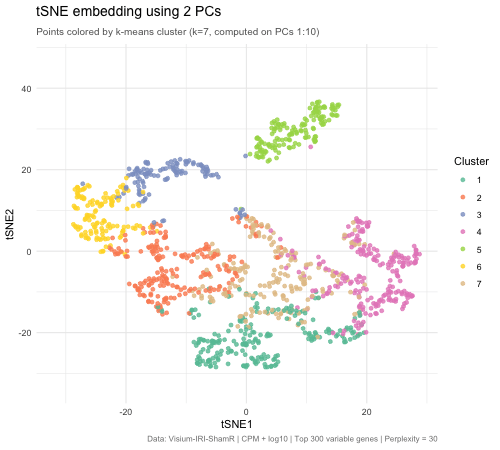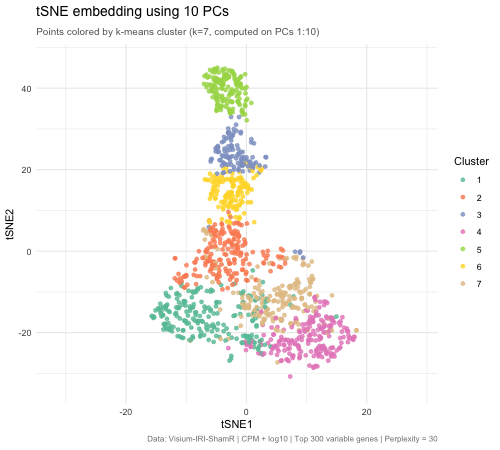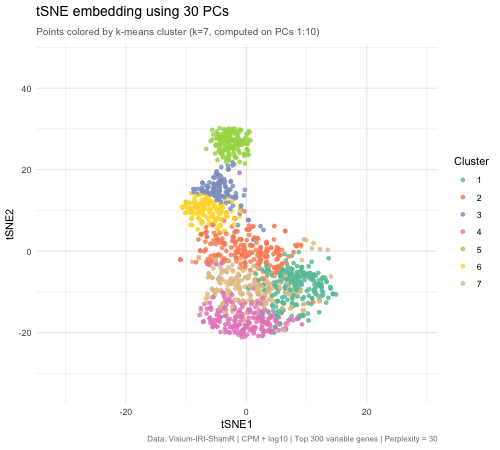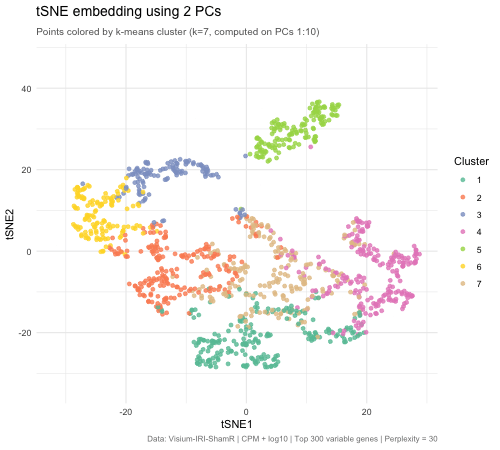
Effect of Varying PC Count on tSNE Space - Visium
Write a a brief description of your figure so we know what you are visualizing.

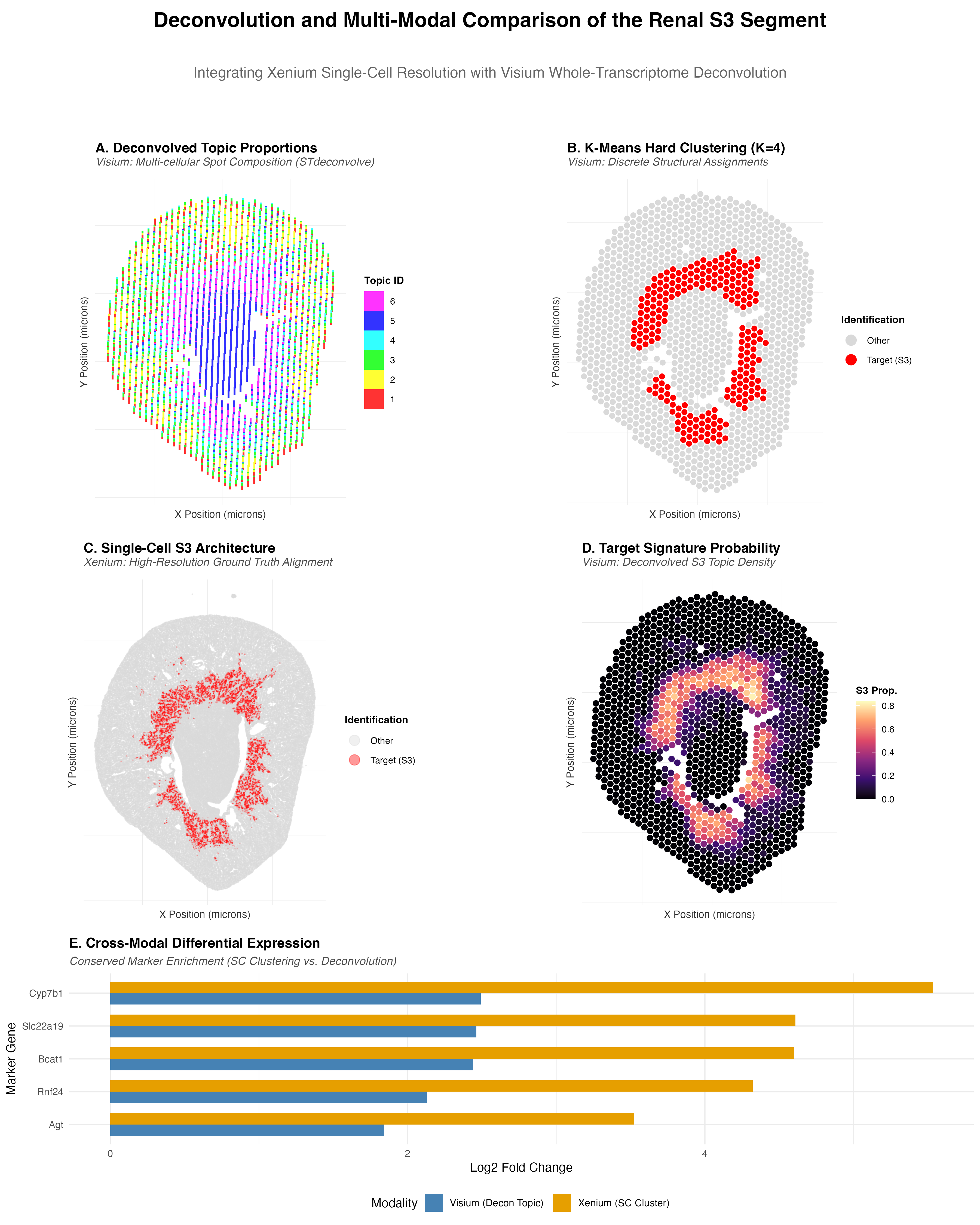
Deconvolution and Multi-Modal Comparison of the Renal S3 Segment
Note, the png is named “EC2_ooni5.png”, as a desired name was not specified in the HW powerpoint.

HW5
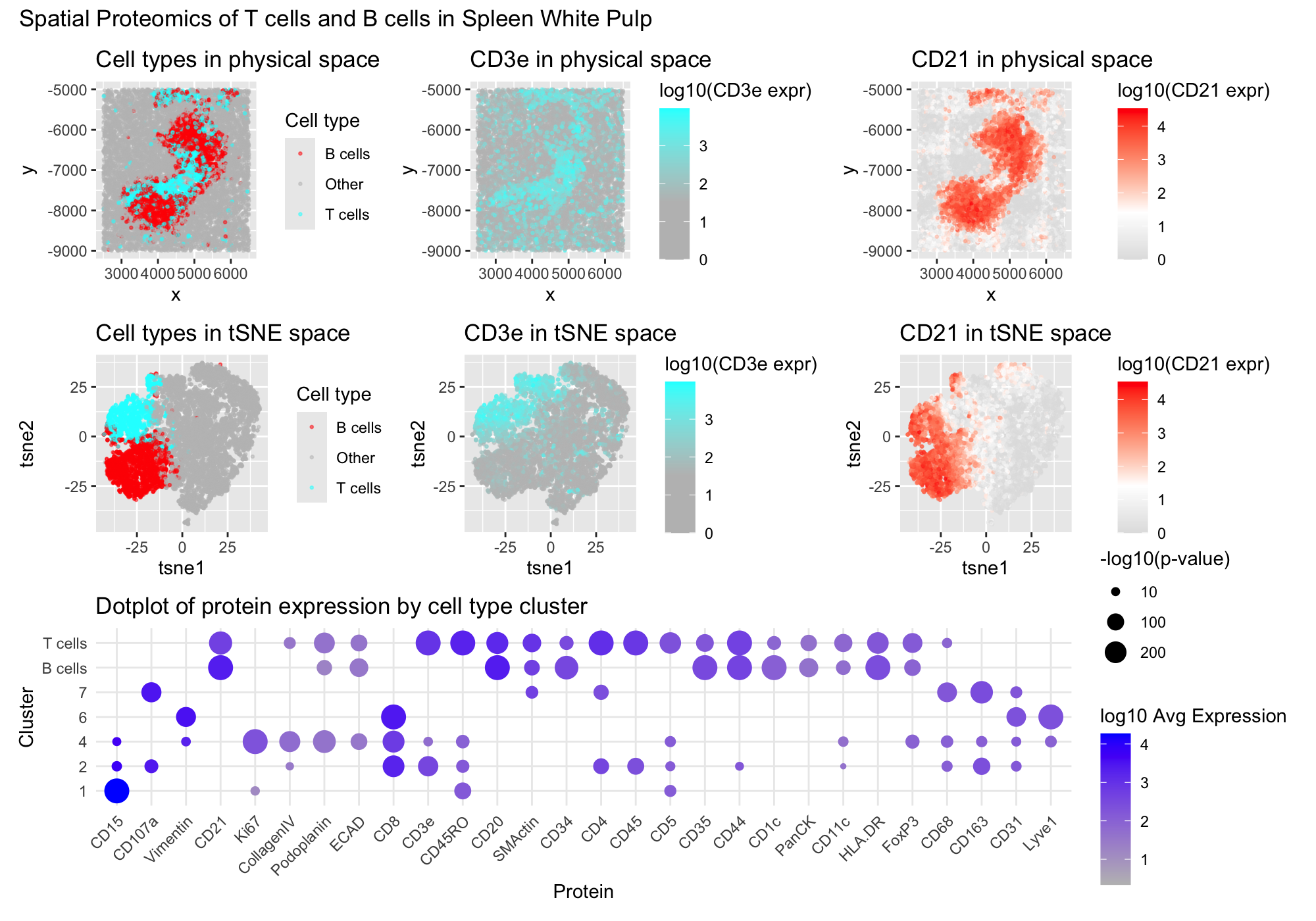
1. Figure Description I created a multipanel figure to show the distribution of B cells and T cells in thhe spleen. Throughout, I used the...

Identification of CODEX data as White Pulp
Perform a full analysis (quality control, dimensionality reduction, kmeans clustering, differential expression analysis) on your data. Your goal is to figure out what tissue structure...
HW 5
###Summary To identify the tissue structure represented in this CODEX dataset, I performed quality control, dimensionality reduction, k means clustering, differential expression analysis, and cell-type...

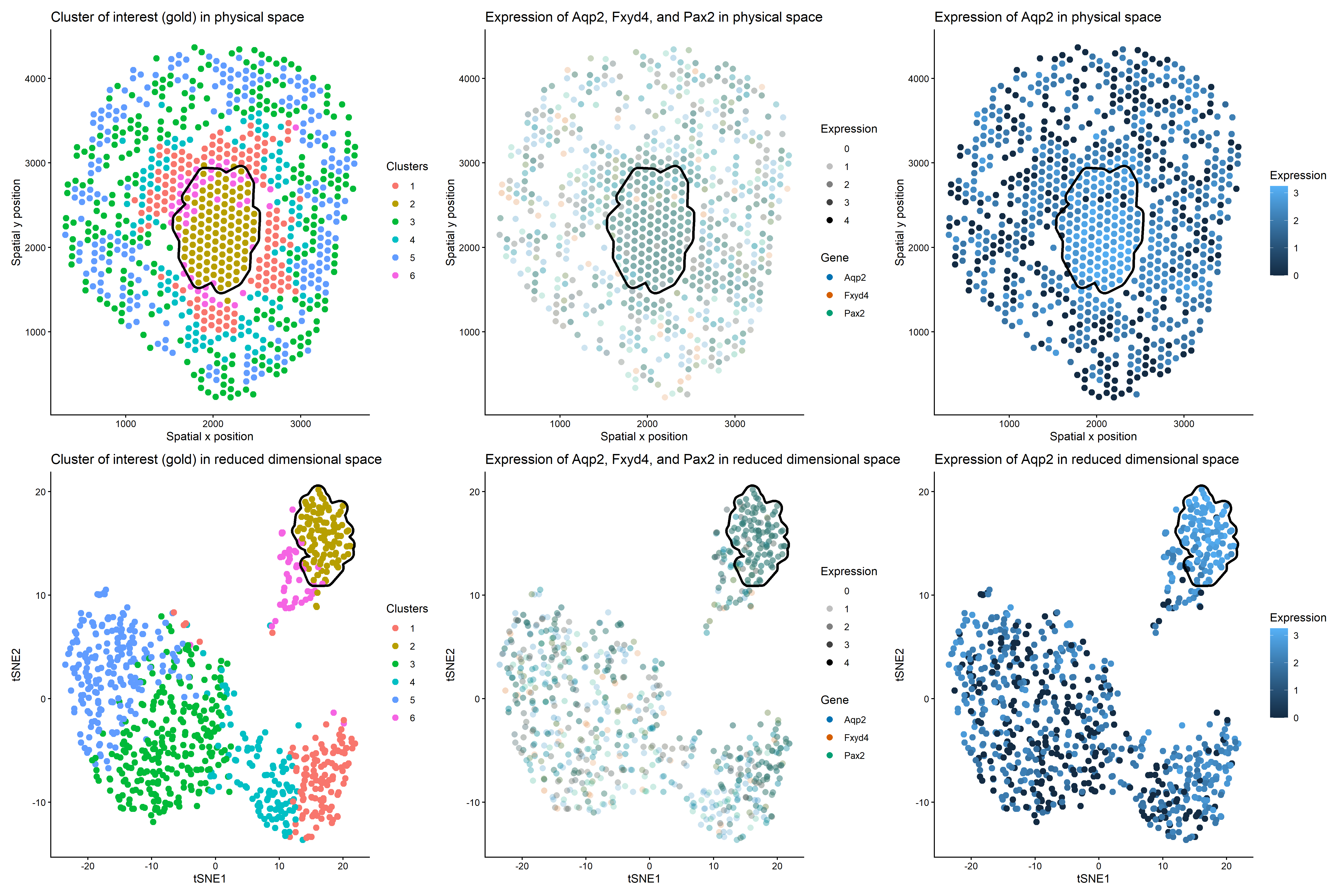
Identification of kidney collecting duct principal cells through dimensionality reduction, k-means clustering, and differential expression analysis
1. Figure description This multi-panel data visualization uses principal component analysis (PCA), t-distributed stochastic neighbor embedding (tSNE), k-means clustering, and differential expression analysis to characterize...
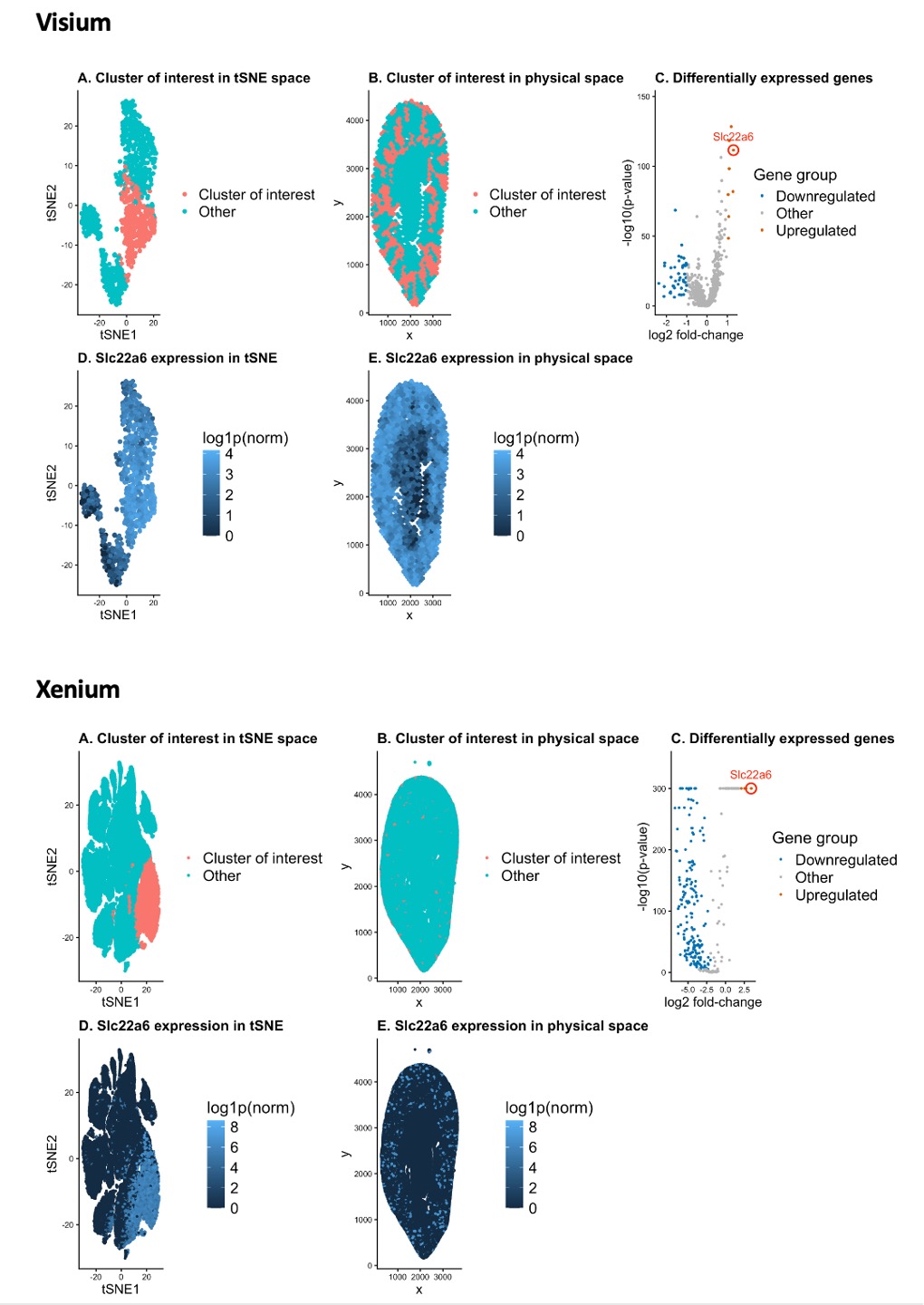
hw4: cortical tubule area in Xenium data
I’ve been analyzing Visium data so far, and this time I switched to Xenium data to try to identify the same cell type I found...

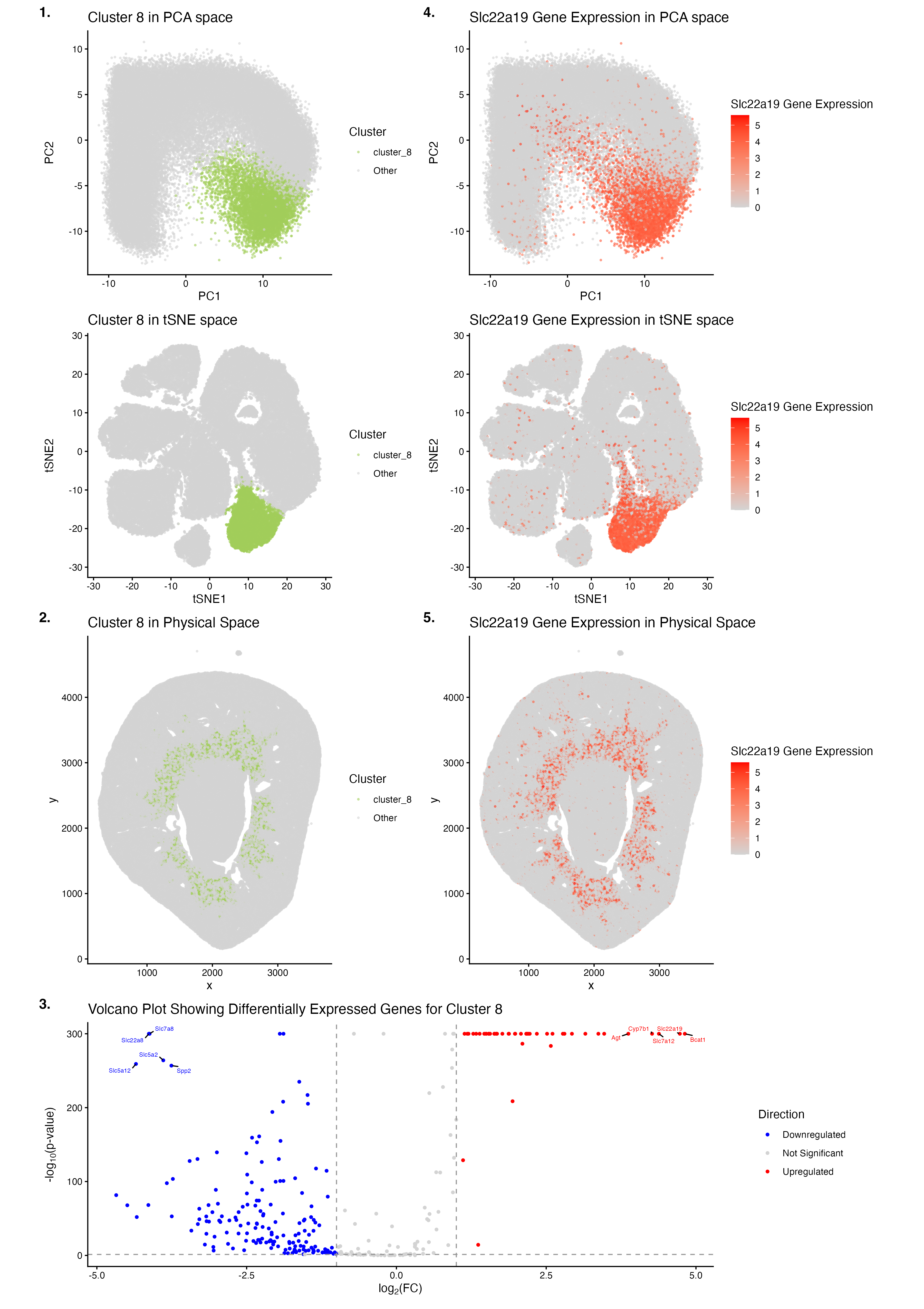
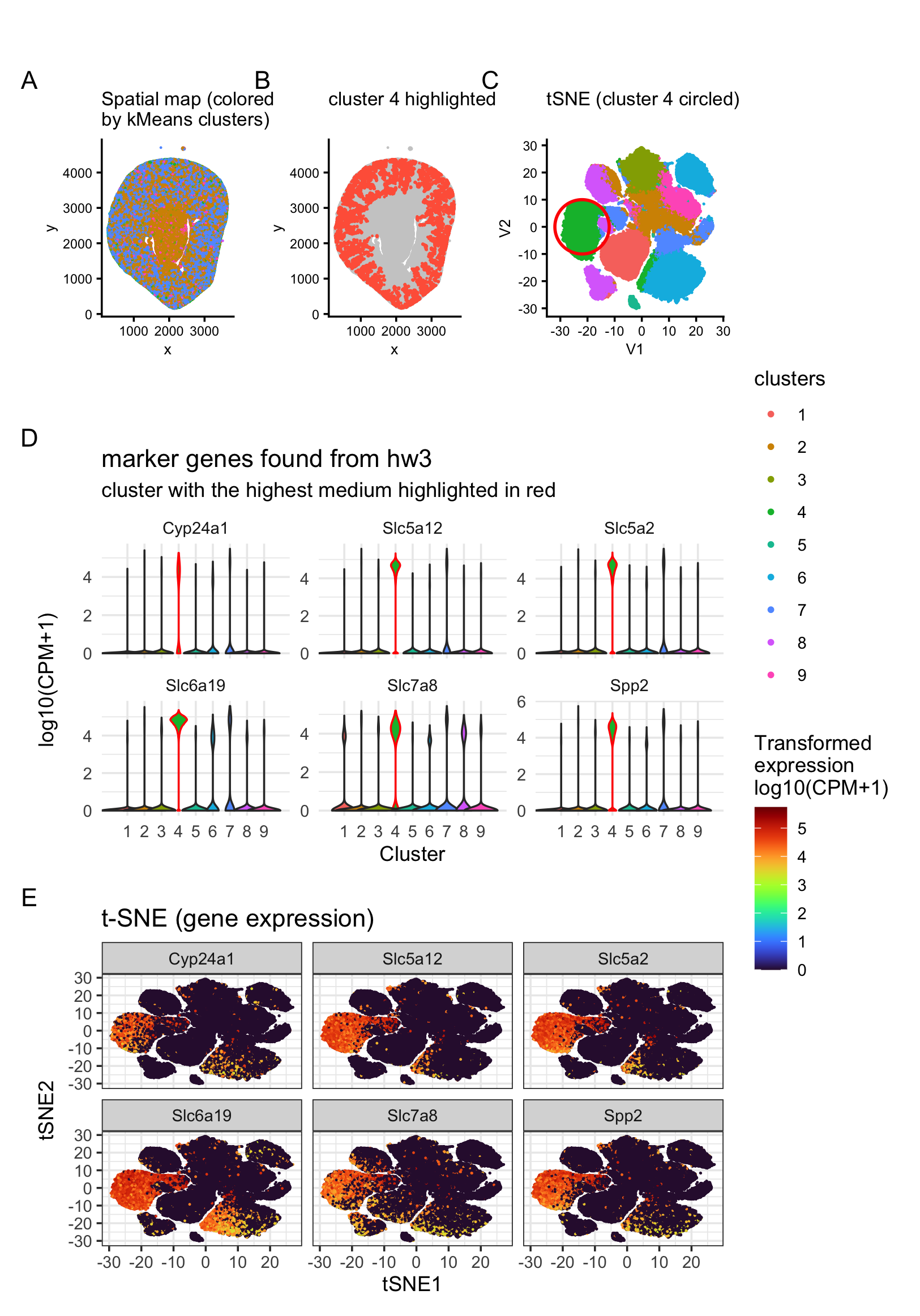
HW3: Multi-Panel Data Visualization of a Transcriptionally Distinct Proximal Tubule Epithelial Cell Cluster in the Xenium Dataset
Describe your figure briefly so we know what you are depicting (you no longer need to use precise data visualization terms as you have been...

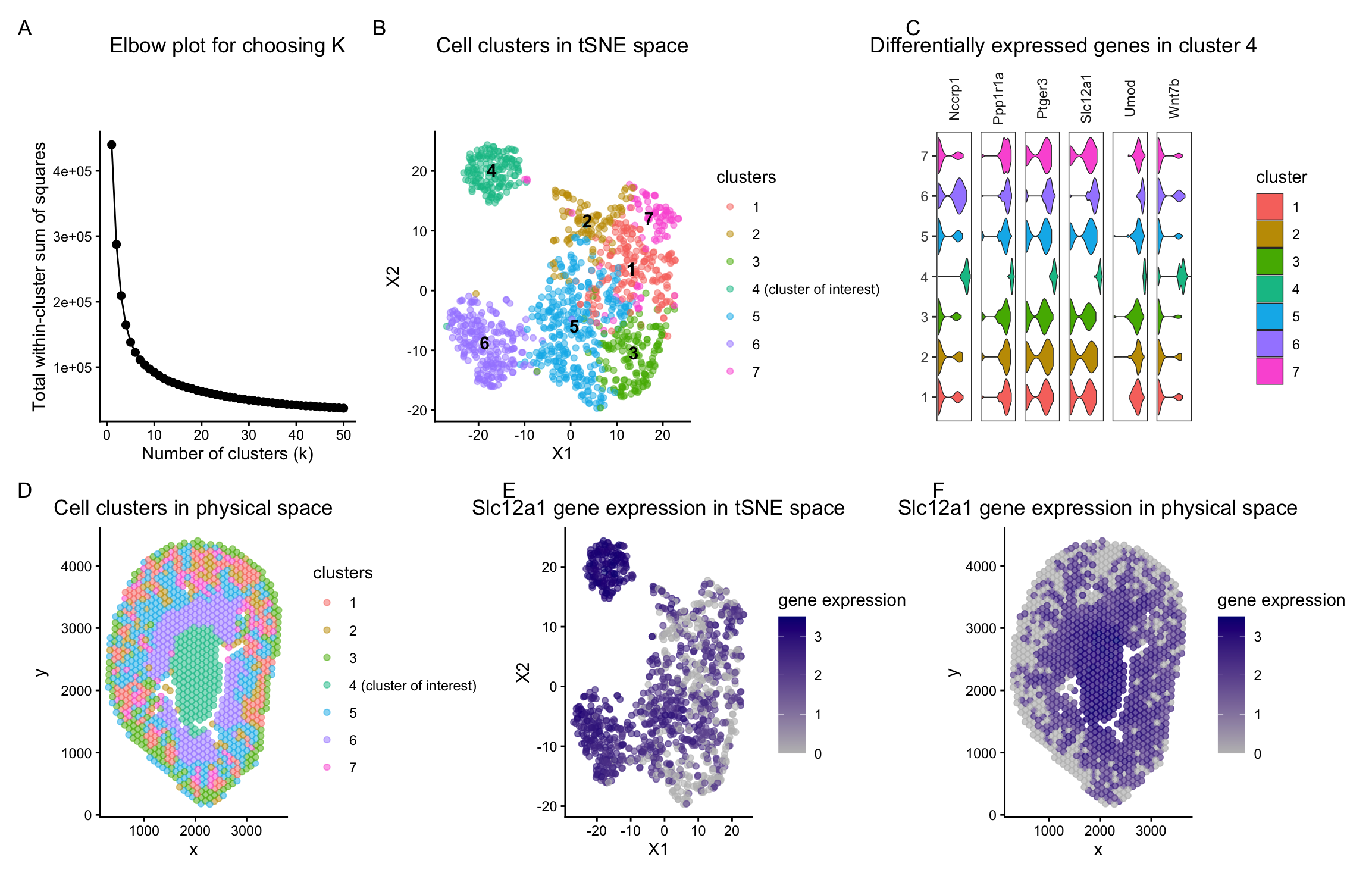
A multipanel data visualization distinguishing the ascending loop of henle in mouse kidney tissue
Describe your figure briefly so we know what you are depicting (you no longer need to use precise data visualization terms as you have been...

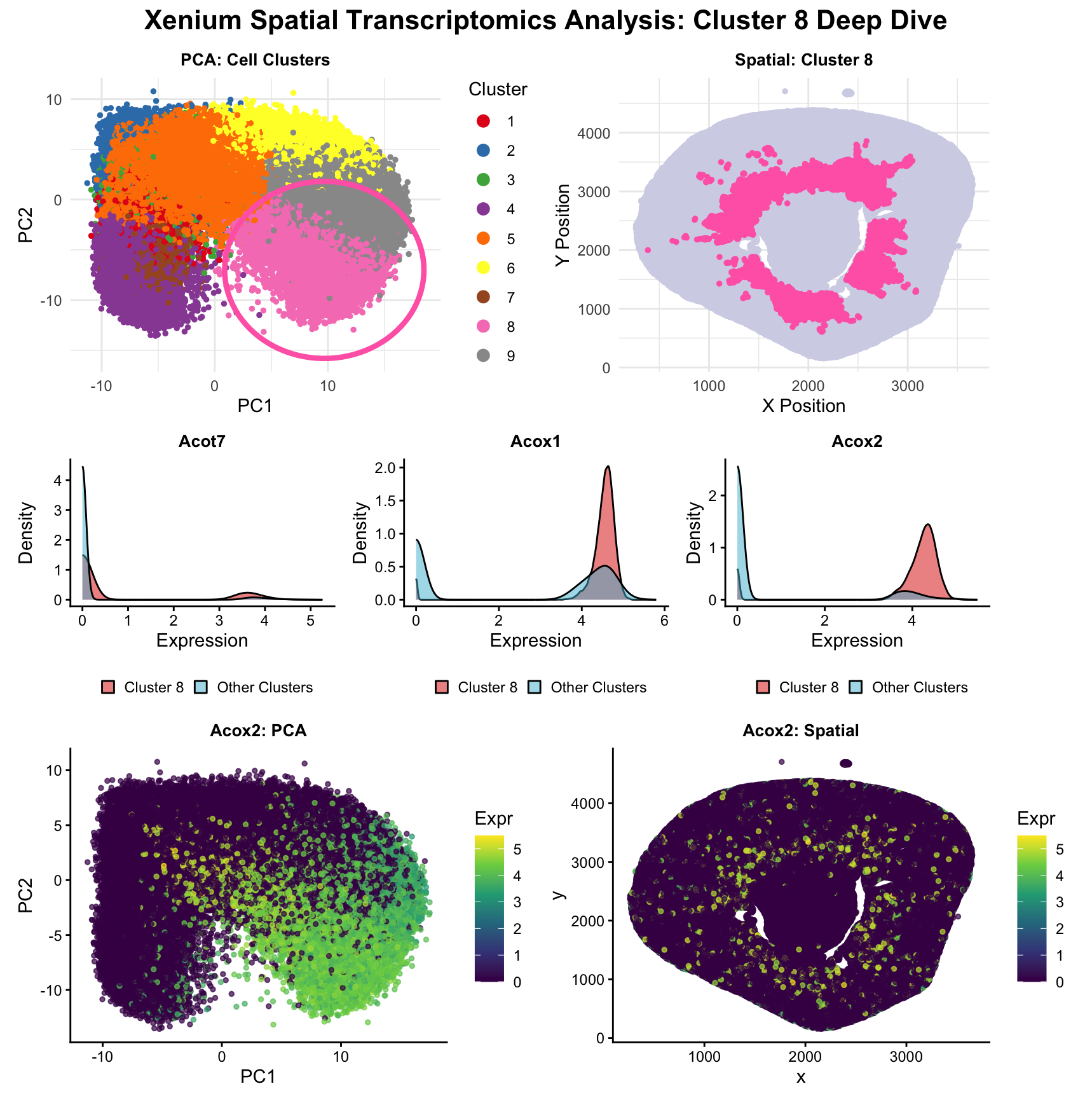
Visualization of Proximal Tubule Cells in Kidney Tissue Sample
Description of Data Visualization: The raw Xenium dataset was normalized according to library size and log normalization before having its dimensionality reduced using principal component...

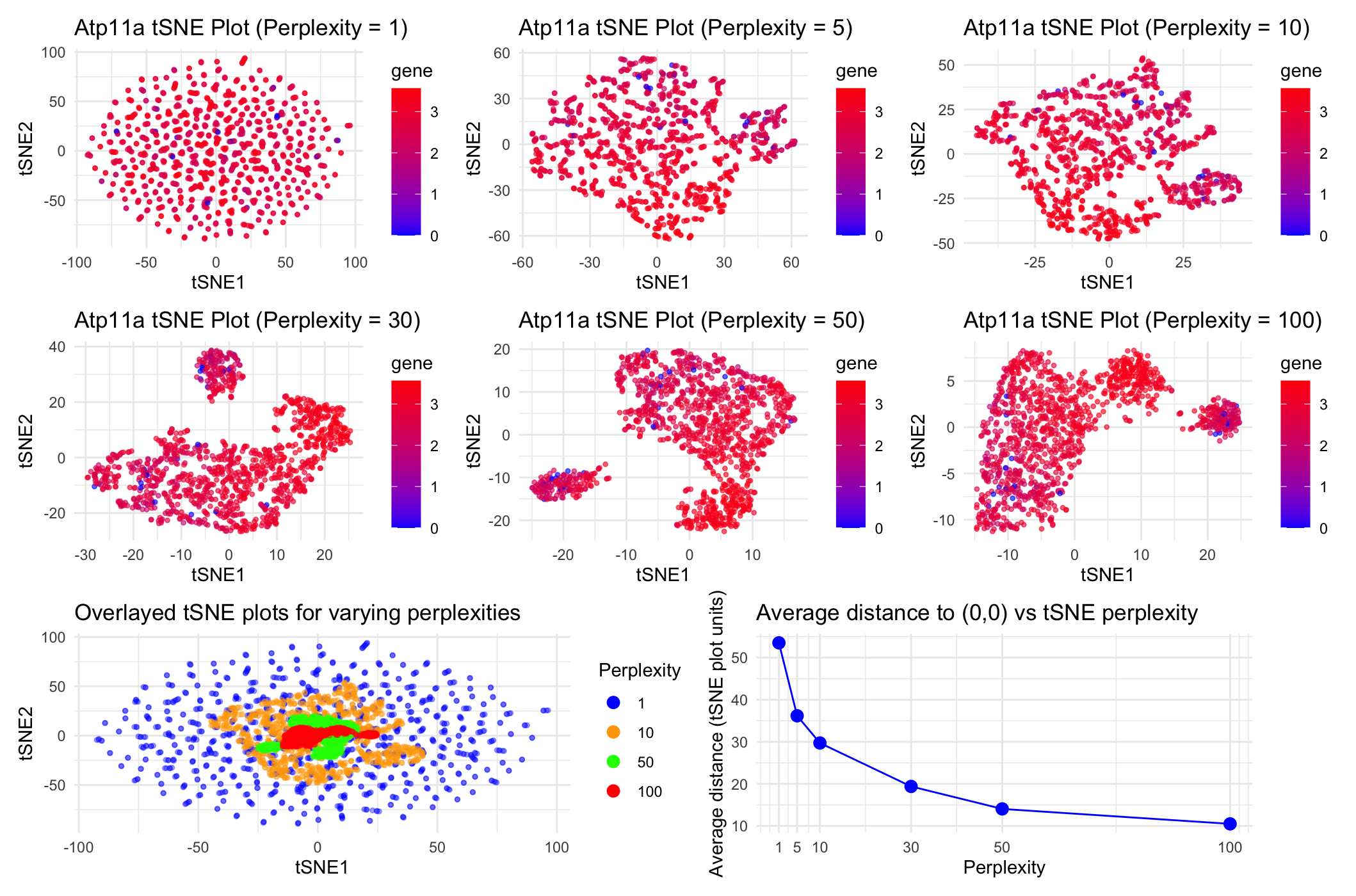
HW2
Question explored: “How do tSNE coordinates change as you increase or decrease the perplexity?”

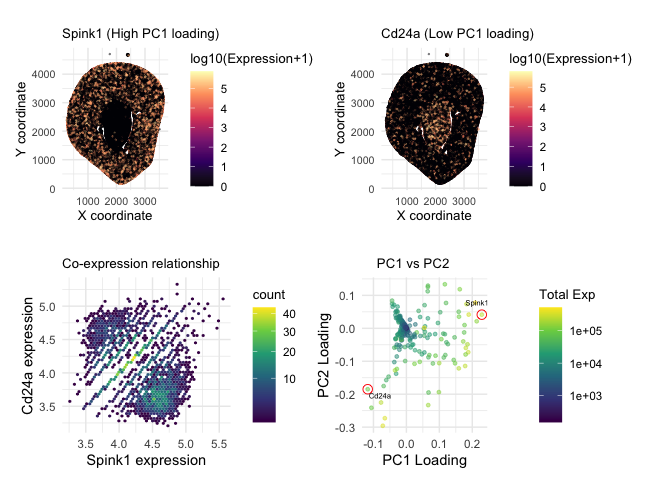
Comparing high vs. low PC1 loading genes
Aim: How do the genes with high versus low loadings relate to each other? How are they patterned relative to each other in the tissue?...

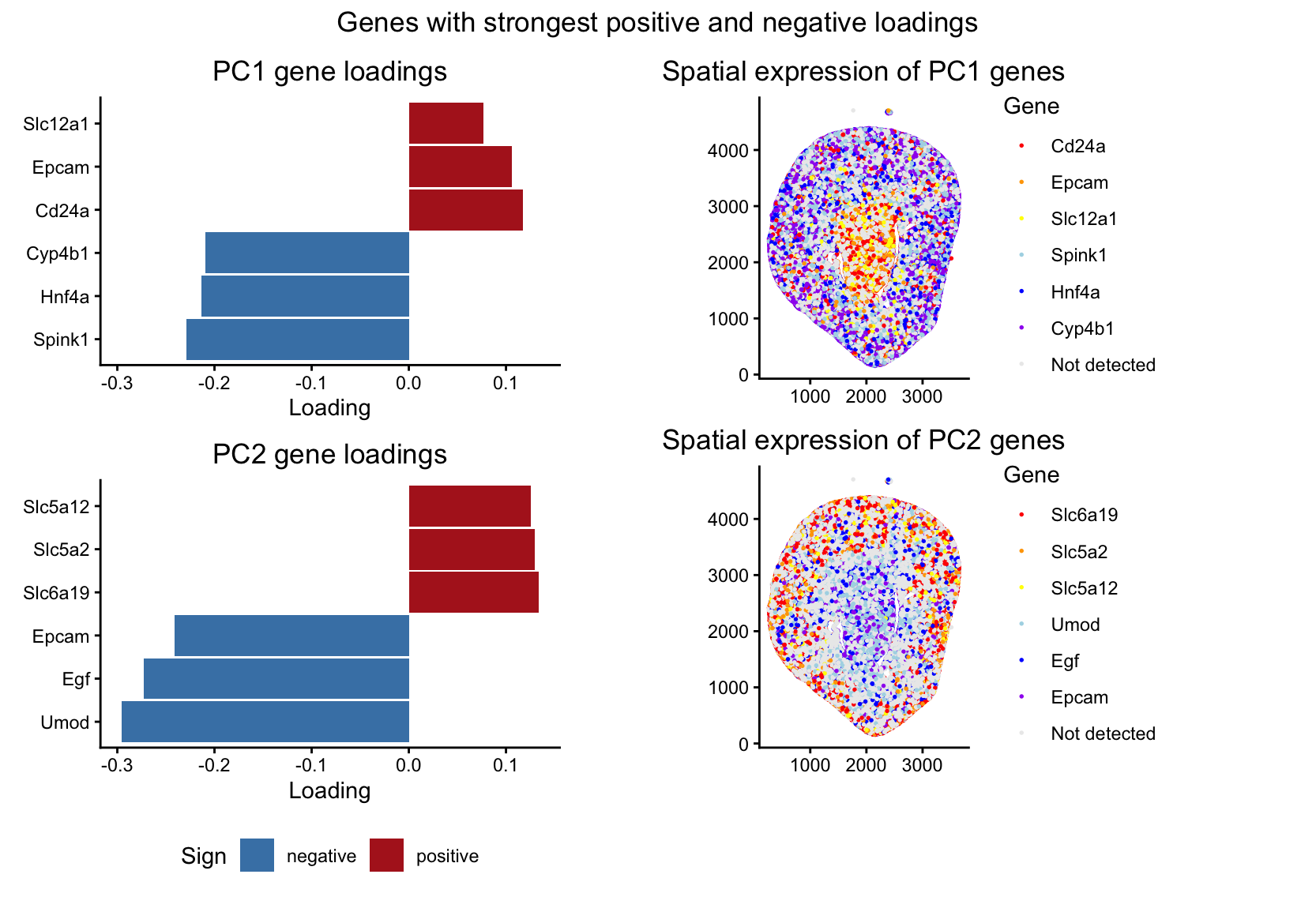
Spatial Organization of Genes with Extreme PCA Loadings
1. What data types are you visualizing? I’m visualizing both quantitative and categorical data. The dataset has quantitative spatial information of x and y coordinates...
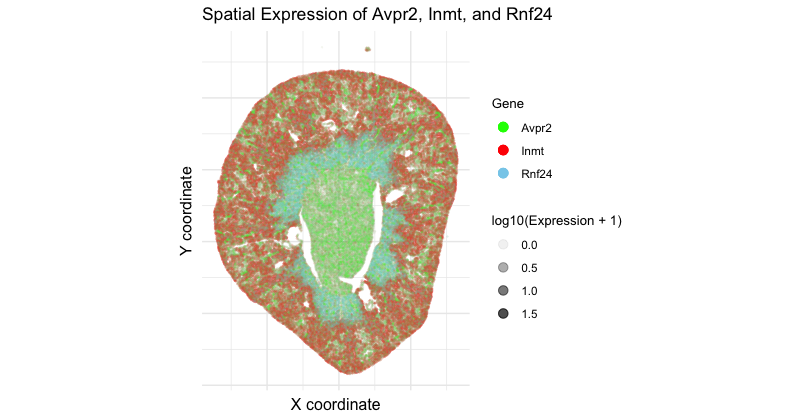
Spatial Expression of Avpr2, Inmt, and Rnf24
1. What data types are you visualizing? I am visualizing 3 data types. First, categorical data of 3 genes: Avpr2, Inmt, and Rnf24. Second, spatial...
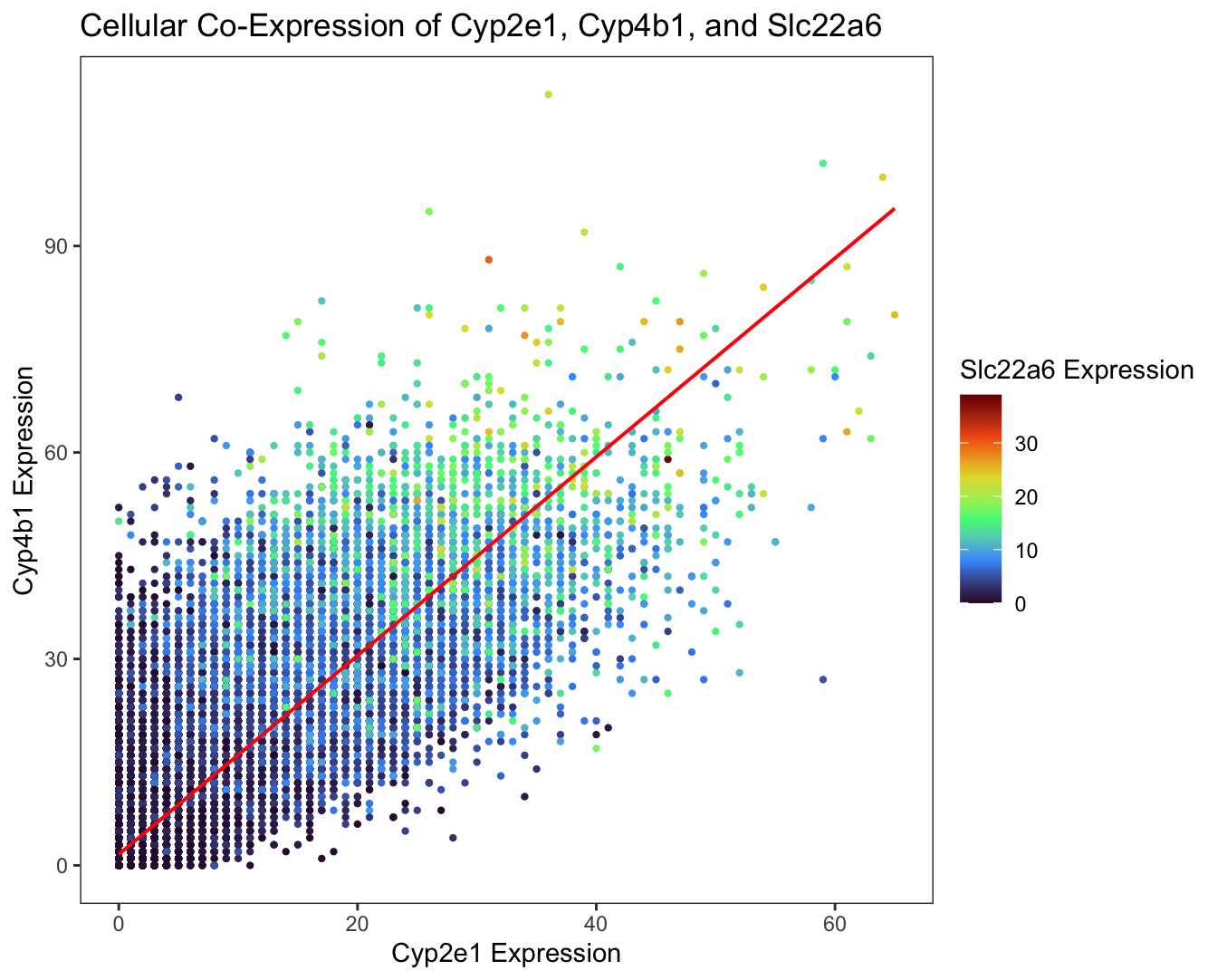
HW1 Submission
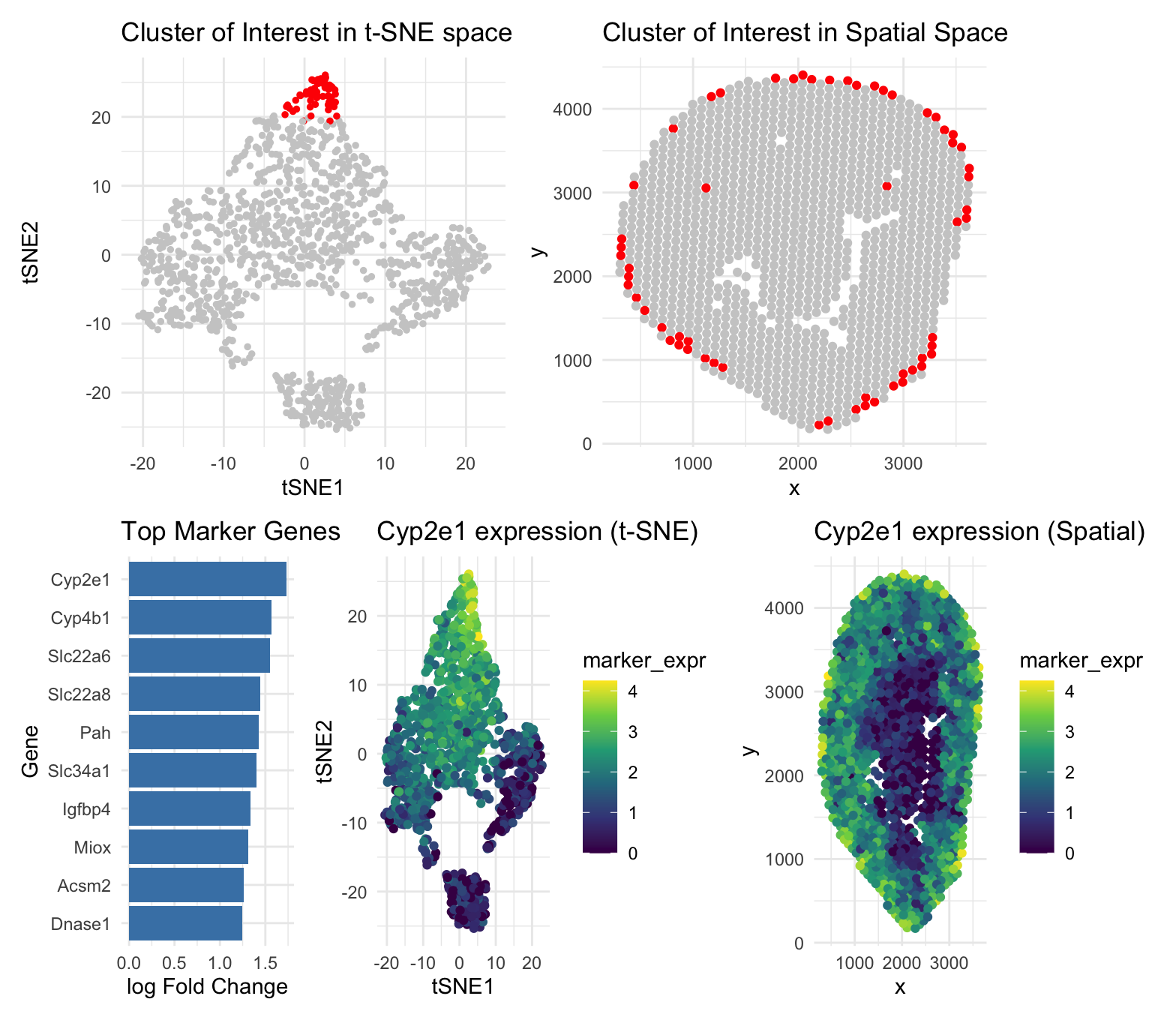
1. What data types are you visualizing? I am visualizing quantitative data of the gene expression counts of the Cyp2e1, Cyp4b1, and Slc22a6 genes for...
HW1
1. What about the data would you like to make salient through this data visualization? Since I am working with Visium 10x geneomics data, every...

All Visualizations
hw4: cortical tubule area in Xenium data
I’ve been analyzing Visium data so far, and this time I switched to Xenium data to try to identify the same cell type I found in HW3 using Visium. However,...
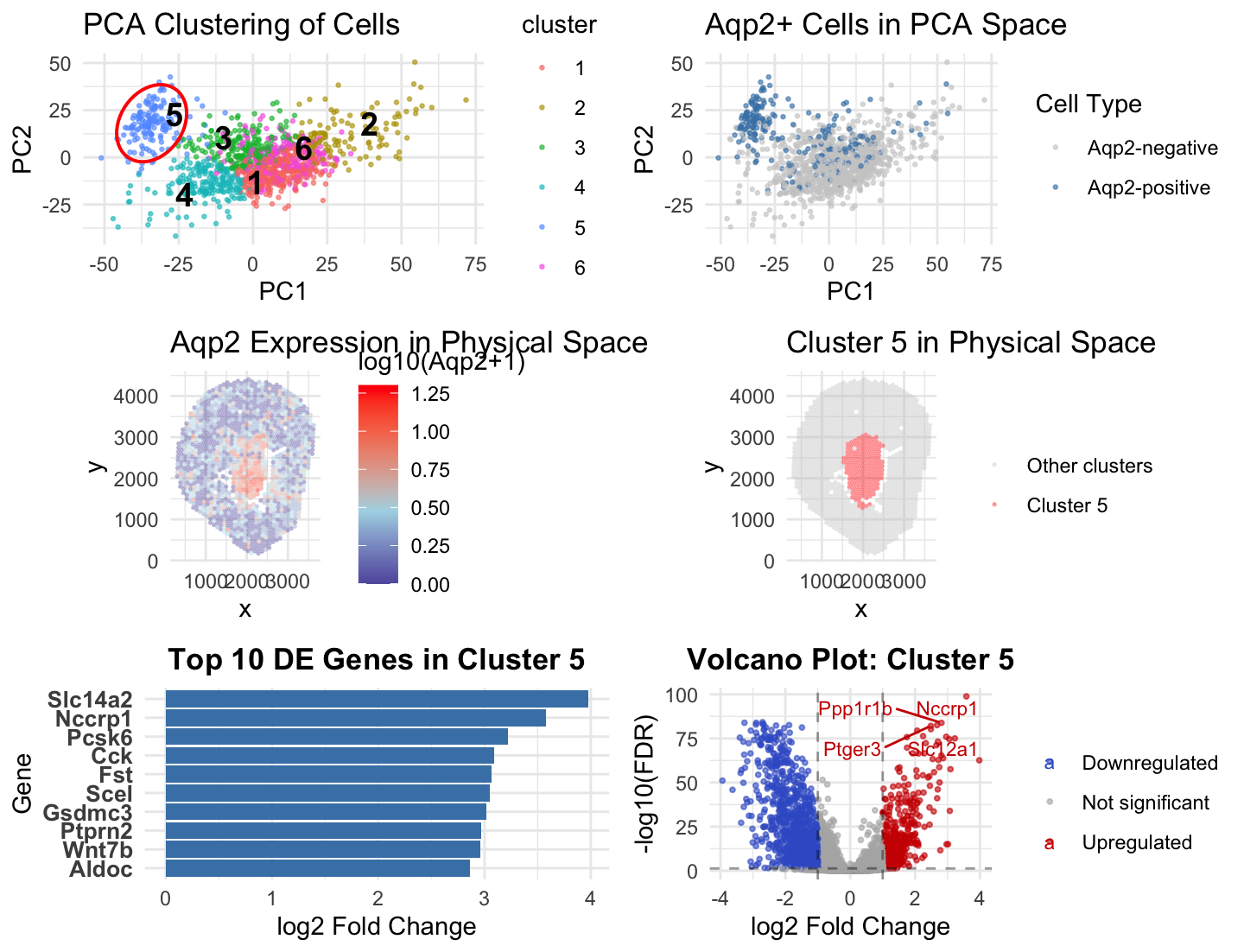
HW 4
Figure Description and Interpretation In Homework 3, I analyzed the Xenium dataset using k-means clustering with k = 10 and identified cluster 3 as an Aqp2-enriched population corresponding to collecting...

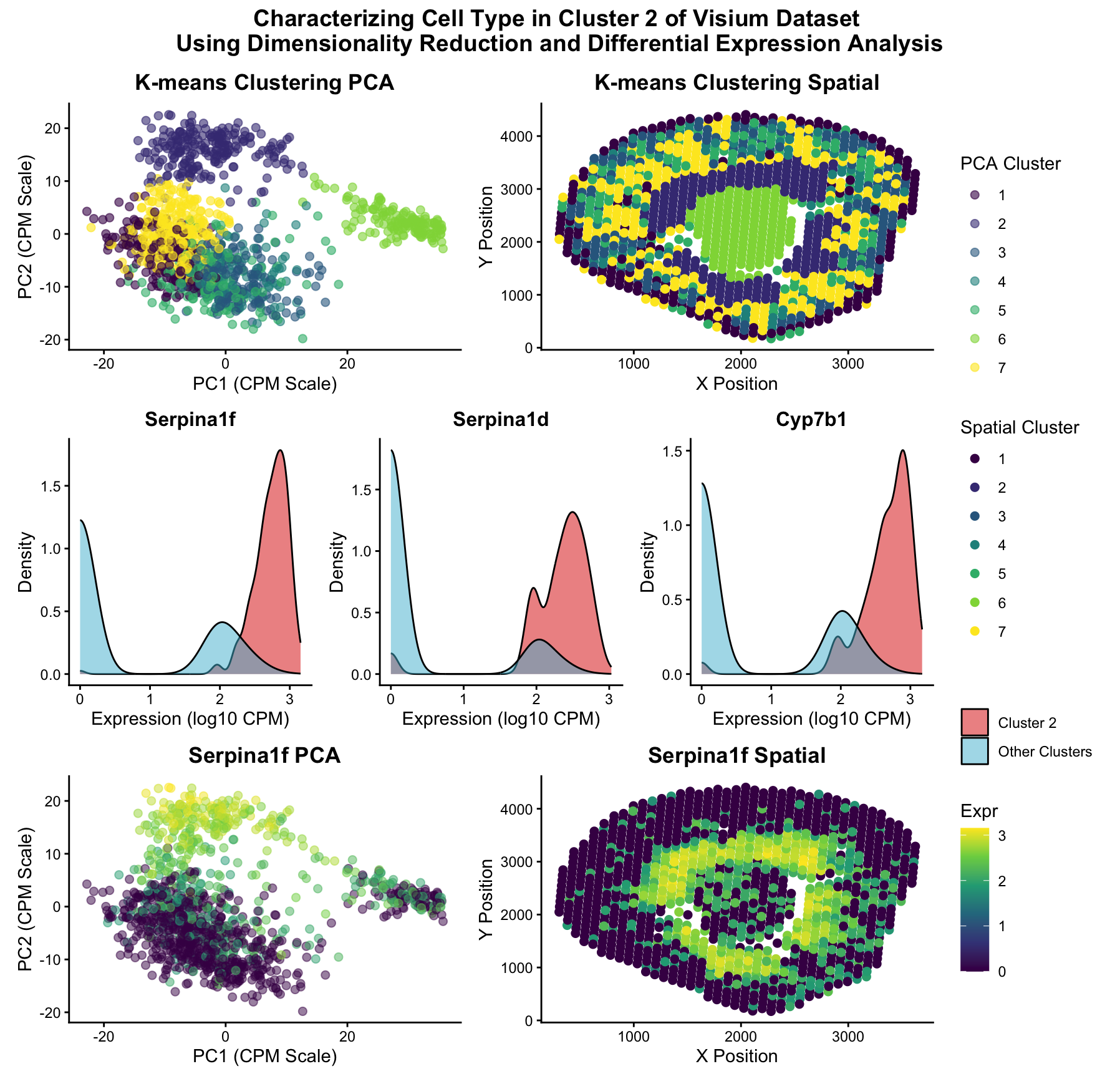
Characterizing Cell Type in Cluster 2 of Visium Dataset Using Dimensionality Reduction and Differential Expression Analysis
Description of Data Visualization: The Visium dataset was normalized (CPM) and its dimensionality was reduced using principal component analysis. The data was then plotted in 2 dimensional (PC1, PC2) space...
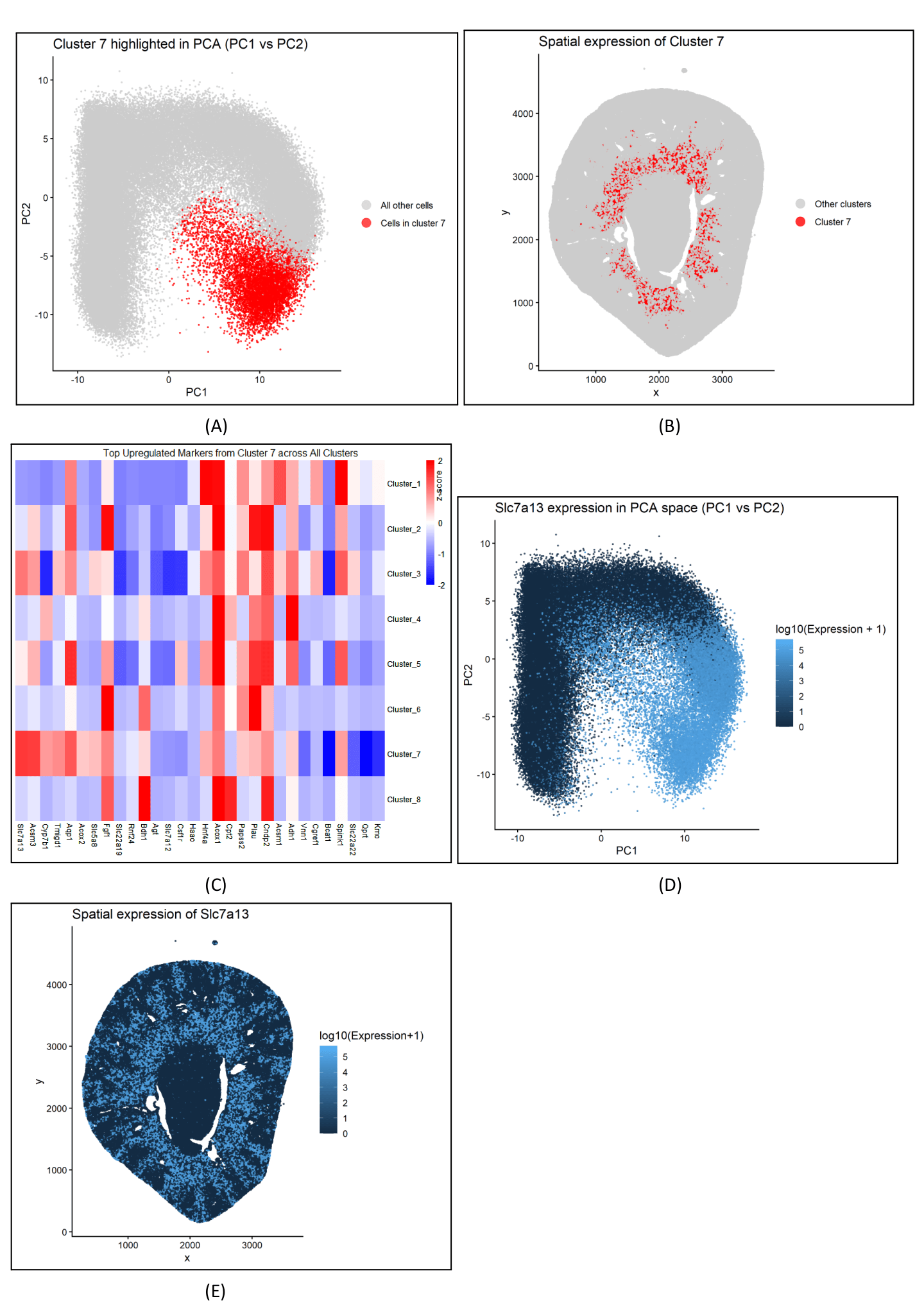
HW 3
Figure description Panel A describes the PCA plot between cluster 7 and all other cells, depicting the distinct separation of cluster 7 in the reduced dimensional space. Panel B visualizes...

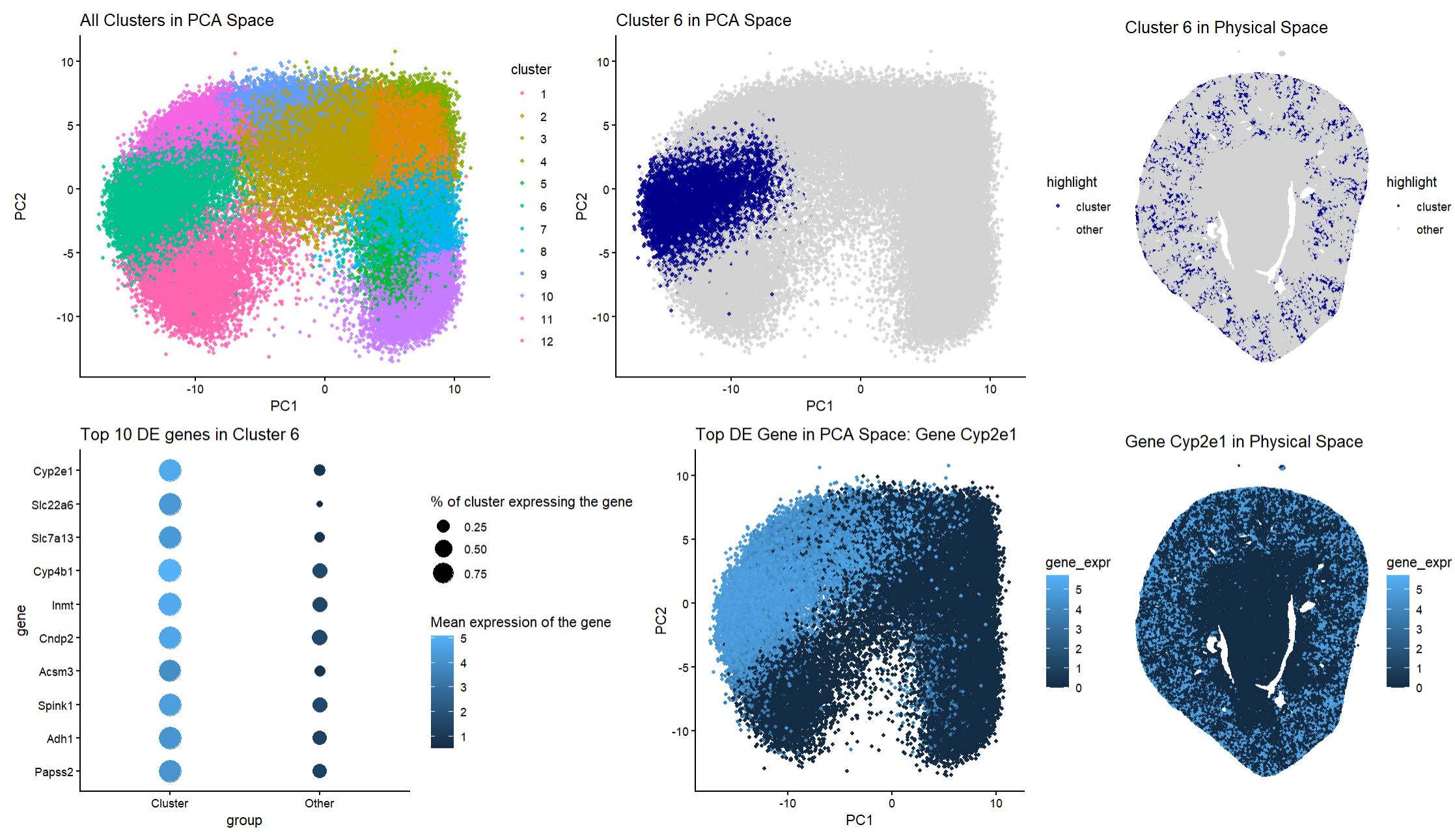

HW3: Multi-Panel Data Visualization of a Transcriptionally Distinct Proximal Tubule Epithelial Cell Cluster in the Xenium Dataset
Describe your figure briefly so we know what you are depicting (you no longer need to use precise data visualization terms as you have been doing). Write a description to...
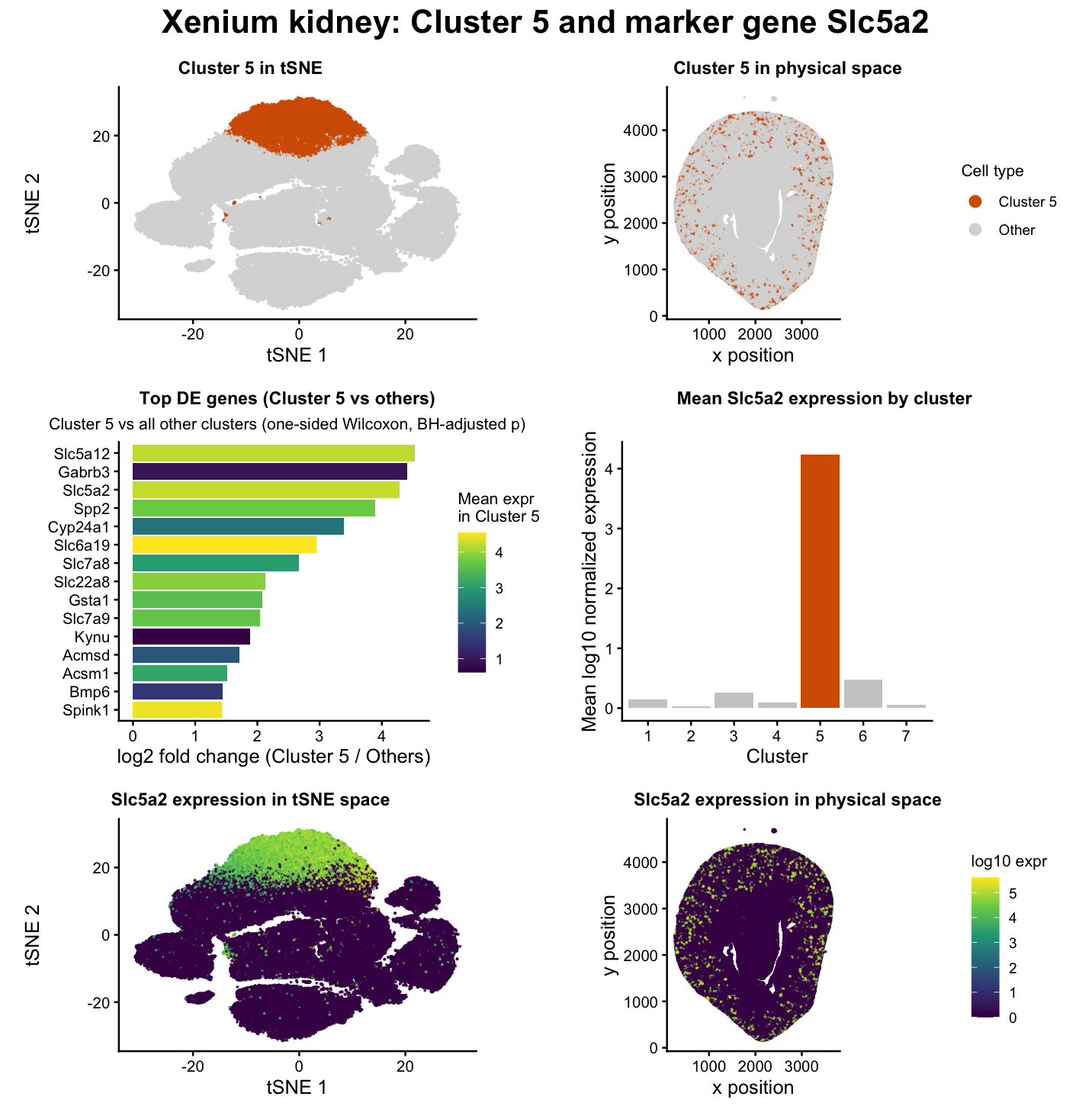
Identifying a kidney cortical tubule region using marker genes
The data were normalized and log-transformed. I then ran PCA on the normalized matrix, used the scree plot of PC standard deviations to pick a safe cutoff (PC = 10)...

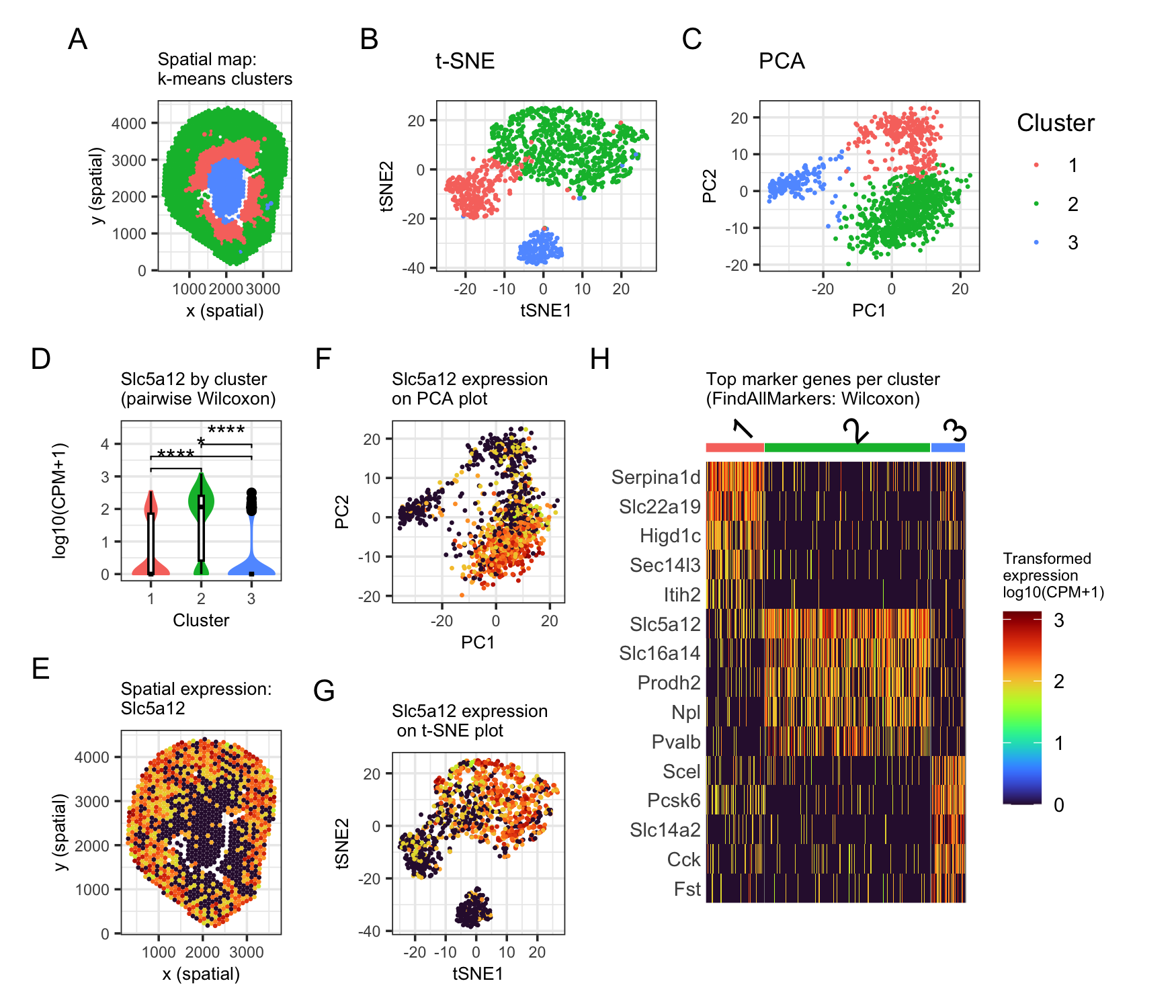
A multipanel data visualization distinguishing the ascending loop of henle in mouse kidney tissue
Describe your figure briefly so we know what you are depicting (you no longer need to use precise data visualization terms as you have been doing). Write a description to...
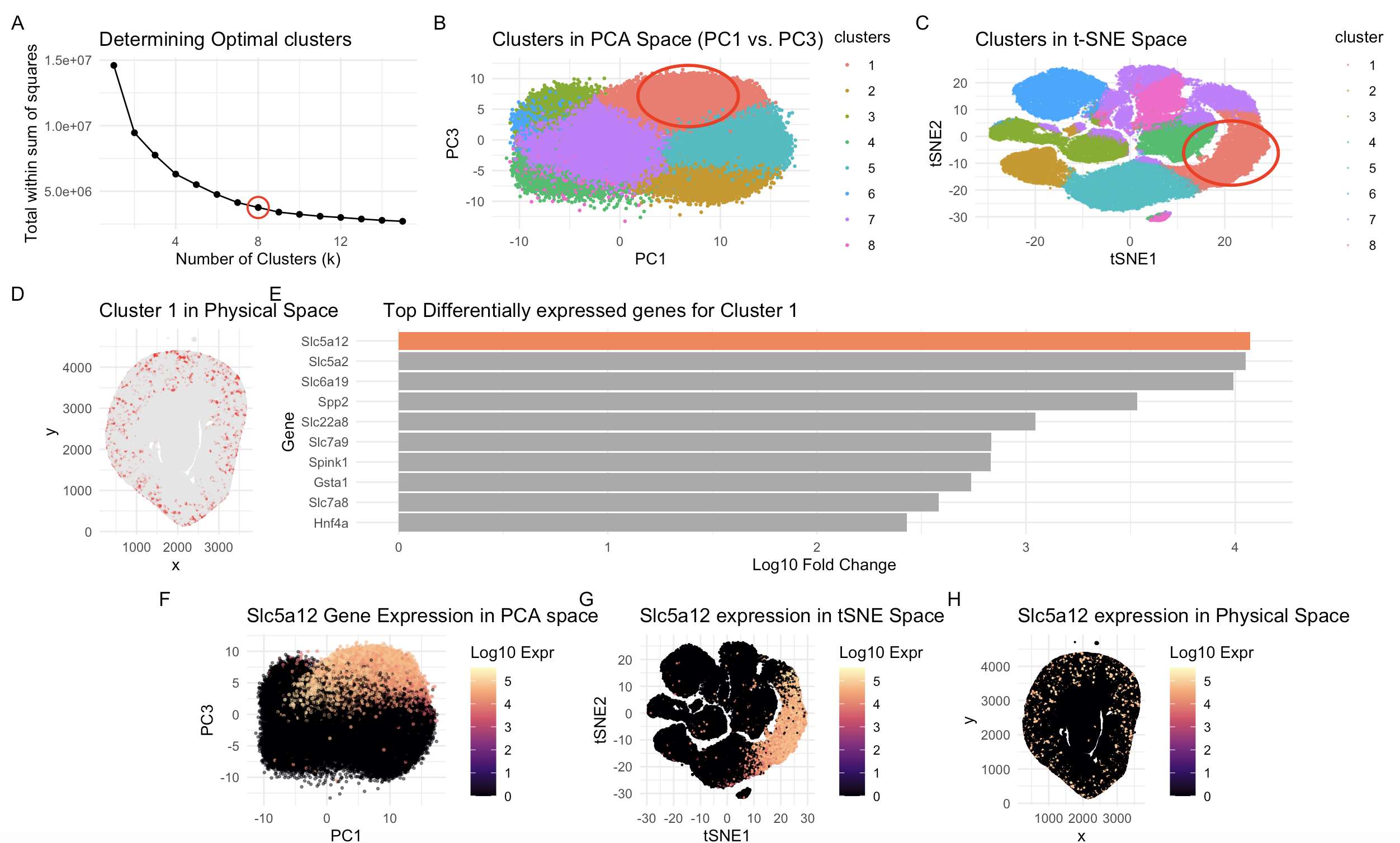
Highlighting Proximal Convoluted Tubule Segments with SLC gene family
Description This multi-panel visualization combines a multitude of concepts essential in spatial transcriptomic data analysis and visualization, including normalization/log-transformation, dimensionality reduction, k-means clustering, and differential expression. By combining these methods,...