Aligning partially matched, serial, single-cell resolution breast cancer spatial transcriptomics data from Xenium
In this notebook, we take two single cell resolution spatial transcriptomics datasets of serial breast cancer sections profiled by the Xenium technology and align them to each other. See the bioRxiv preprint for more details about this data: https://www.biorxiv.org/content/10.1101/2022.10.06.510405v2
We will use STalign to achieve this alignment. We will first load the relevant code libraries.
[5]:
# import dependencies
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import torch
# make plots bigger
plt.rcParams["figure.figsize"] = (10,8)
[6]:
# OPTION A: import STalign after pip or pipenv install
from STalign import STalign
[4]:
## OPTION B: skip cell if installed STalign with pip or pipenv
import sys
sys.path.append("../../STalign")
## import STalign from upper directory
import STalign
We have already downloaded single cell spatial transcriptomics data from and placed the files in a folder called xenium_data: https://www.10xgenomics.com/products/xenium-in-situ/preview-dataset-human-breast
We can read in the cell information for the first dataset using pandas as pd.
[7]:
# Single cell data 1
# read in data
fname = '../xenium_data/Xenium_FFPE_Human_Breast_Cancer_Rep1_cells.csv.gz'
df1 = pd.read_csv(fname)
print(df1.head())
cell_id x_centroid y_centroid transcript_counts control_probe_counts
0 1 377.663005 843.541888 154 0 \
1 2 382.078658 858.944818 64 0
2 3 319.839529 869.196542 57 0
3 4 259.304707 851.797949 120 0
4 5 370.576291 865.193024 120 0
control_codeword_counts total_counts cell_area nucleus_area
0 0 154 110.361875 45.562656
1 0 64 87.919219 24.248906
2 0 57 52.561875 23.526406
3 0 120 75.230312 35.176719
4 0 120 180.218594 34.499375
For alignment with STalign, we only need the cell centroid information. So we can pull out this information. We can further visualize the cell centroids to get a sense of the variation in cell density that we will be relying on for our alignment by plotting using matplotlib.pyplot as plt.
[8]:
# get cell centroid coordinates
xI = np.array(df1['x_centroid'])
yI = np.array(df1['y_centroid'])
# plot
fig,ax = plt.subplots()
ax.scatter(xI,yI,s=1,alpha=0.2)
[8]:
<matplotlib.collections.PathCollection at 0x1081fd4f0>
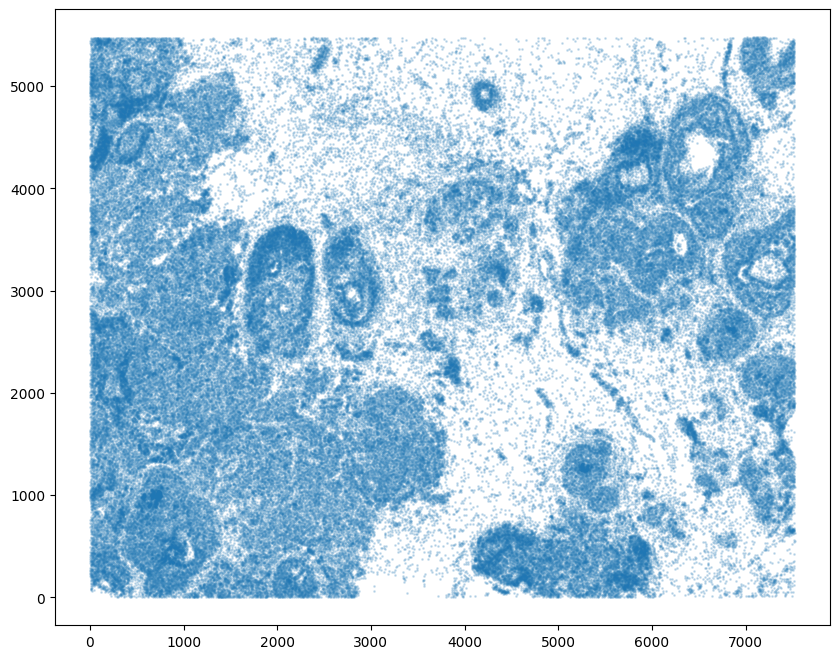
We will first use STalign to rasterize the single cell centroid positions into an image. Assuming the single-cell centroid coordinates are in microns, we will perform this rasterization at a 30 micron resolution. We can visualize the resulting rasterized image.
Note that points are plotting with the origin at bottom left while images are typically plotted with origin at top left so we’ve used invert_yaxis() to invert the yaxis for visualization consistency.
[9]:
# rasterize at 30um resolution (assuming positions are in um units) and plot
XI,YI,I,fig = STalign.rasterize(xI,yI,dx=30)
# plot
ax = fig.axes[0]
ax.invert_yaxis()
0 of 167782
10000 of 167782
20000 of 167782
30000 of 167782
40000 of 167782
50000 of 167782
60000 of 167782
70000 of 167782
80000 of 167782
90000 of 167782
100000 of 167782
110000 of 167782
120000 of 167782
130000 of 167782
140000 of 167782
150000 of 167782
160000 of 167782
167781 of 167782

Now, we can repeat this for the cell information from the second dataset.
[10]:
# Single cell data 2
# read in data
fname = '../xenium_data/Xenium_FFPE_Human_Breast_Cancer_Rep2_cells.csv.gz'
df2 = pd.read_csv(fname)
# get cell centroids
xJ = np.array(df2['x_centroid'])
yJ = np.array(df2['y_centroid'])
# plot
fig,ax = plt.subplots()
ax.scatter(xJ,yJ,s=1,alpha=0.2,c='#ff7f0e')
# rasterize and plot
XJ,YJ,J,fig = STalign.rasterize(xJ,yJ,dx=30)
ax = fig.axes[0]
ax.invert_yaxis()
0 of 118752
10000 of 118752
20000 of 118752
30000 of 118752
40000 of 118752
50000 of 118752
60000 of 118752
70000 of 118752
80000 of 118752
90000 of 118752
100000 of 118752
110000 of 118752
118751 of 118752
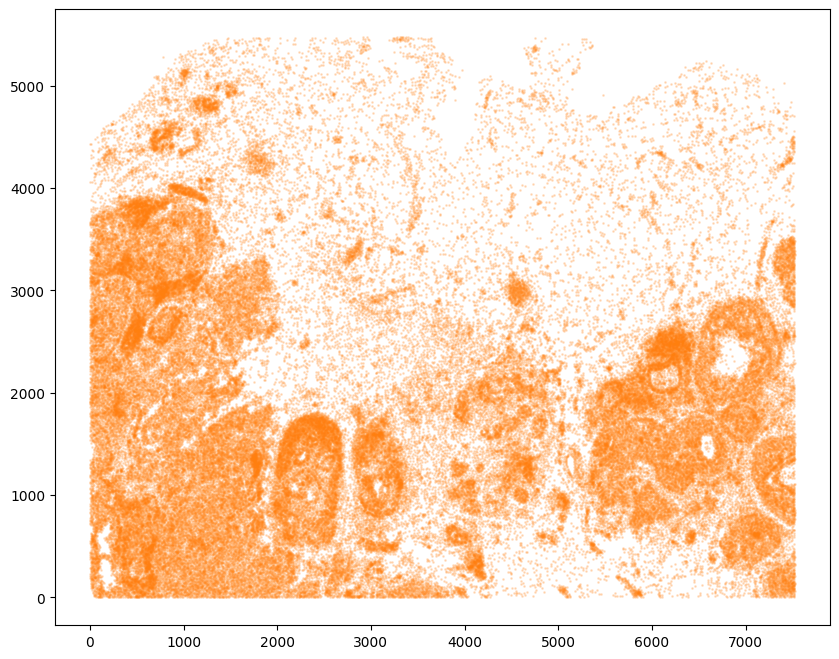

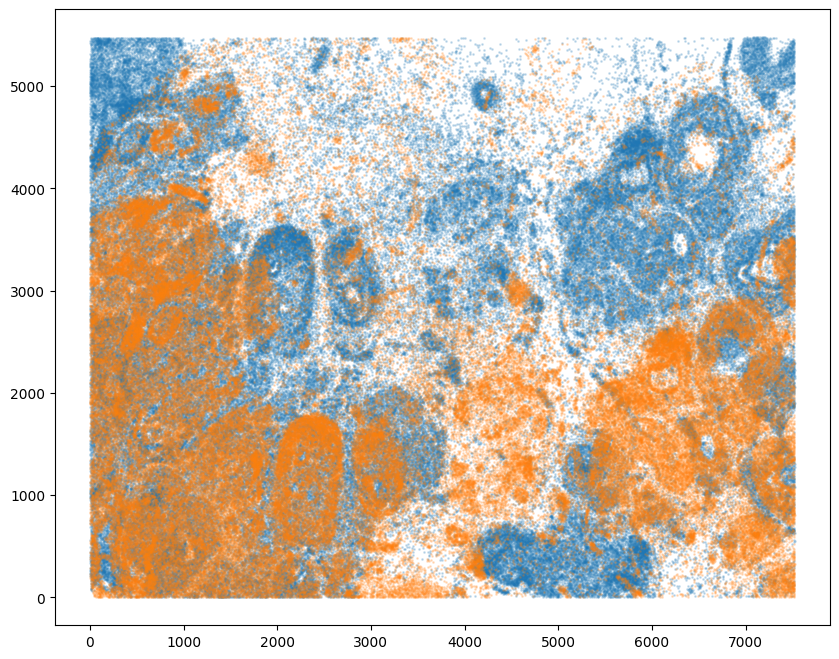
Note that plotting the cell centroid positions from both datasets shows that alignment is still needed.
[11]:
# plot
fig,ax = plt.subplots()
ax.scatter(xI,yI,s=1,alpha=0.2)
ax.scatter(xJ,yJ,s=1,alpha=0.2)
[11]:
<matplotlib.collections.PathCollection at 0x155766ee0>
STalign relies on an interative gradient descent to align these two images. This can be somewhat slow. So we can manually designate a few landmark points to help initialize the alignment. A curve_annotator.py script is provided to assist with this. In order to use the curve_annotator.py script, we will need to write out our images as .npz files.
[56]:
# Optional: write out npz files for landmark point picker
np.savez('../xenium_data/Xenium_Breast_Cancer_Rep1', x=XI,y=YI,I=I)
np.savez('../xenium_data/Xenium_Breast_Cancer_Rep2', x=XJ,y=YJ,I=J)
# outputs Xenium_Breast_Cancer_Rep1.npz and Xenium_Breast_Cancer_Rep2.npz
Given these .npz files, we can then run the following code:
python curve_annotator.py Xenium_Breast_Cancer_Rep1.npz
python curve_annotator.py Xenium_Breast_Cancer_Rep2.npz
Which will provide a graphical user interface to selecting landmark points, which will then be saved in Xenium_Breast_Cancer_Rep1_points.npy and Xenium_Breast_Cancer_Rep2_points.npy respectively. We can then read in these files.
[12]:
# read from file
pointsIlist = np.load('../xenium_data/Xenium_Breast_Cancer_Rep1_points.npy', allow_pickle=True).tolist()
print(pointsIlist)
pointsJlist = np.load('../xenium_data/Xenium_Breast_Cancer_Rep2_points.npy', allow_pickle=True).tolist()
print(pointsJlist)
{'0': [(2065.0390375683187, 3096.538441761356)], '1': [(6505.52290853606, 4365.248119180711)], '2': [(4226.85355369735, 4932.828764342001)]}
{'0': [(2365.8569852416354, 1218.8582693193312)], '1': [(6839.7279529835705, 2387.4066564161058)], '2': [(4552.711823951313, 3046.801817706428)]}
Note that these landmark points are read in as lists. We will want to convert them to a simple array for downstream usage.
[13]:
# convert to array
pointsI = []
pointsJ = []
# Jean's note: a bit odd to me that the points are stored as y,x
## instead of x,y but all downstream code uses this orientation
for i in pointsIlist.keys():
pointsI.append([pointsIlist[i][0][1], pointsIlist[i][0][0]])
for i in pointsJlist.keys():
pointsJ.append([pointsJlist[i][0][1], pointsJlist[i][0][0]])
pointsI = np.array(pointsI)
pointsJ = np.array(pointsJ)
[14]:
# now arrays
print(pointsI)
print(pointsJ)
[[3096.53844176 2065.03903757]
[4365.24811918 6505.52290854]
[4932.82876434 4226.8535537 ]]
[[1218.85826932 2365.85698524]
[2387.40665642 6839.72795298]
[3046.80181771 4552.71182395]]
Alternatively, you can also just manually create an array of points.
But it will be good to double check that your landmark points look sensible by plotting them along with the rasterized image we created.
[15]:
# get extent of images
extentI = STalign.extent_from_x((YI,XI))
extentJ = STalign.extent_from_x((YJ,XJ))
# plot rasterized images
fig,ax = plt.subplots(2,1)
ax[0].imshow((I.transpose(1,2,0).squeeze()), extent=extentI) # just want 201x276 matrix
ax[1].imshow((J.transpose(1,2,0).squeeze()), extent=extentJ) # just want 201x276 matrix
# with points
ax[0].scatter(pointsI[:,1], pointsI[:,0], c='red')
ax[1].scatter(pointsJ[:,1], pointsJ[:,0], c='red')
for i in range(pointsI.shape[0]):
ax[0].text(pointsI[i,1],pointsI[i,0],f'{i}', c='red')
ax[1].text(pointsJ[i,1],pointsJ[i,0],f'{i}', c='red')
ax[0].invert_yaxis()
ax[1].invert_yaxis()
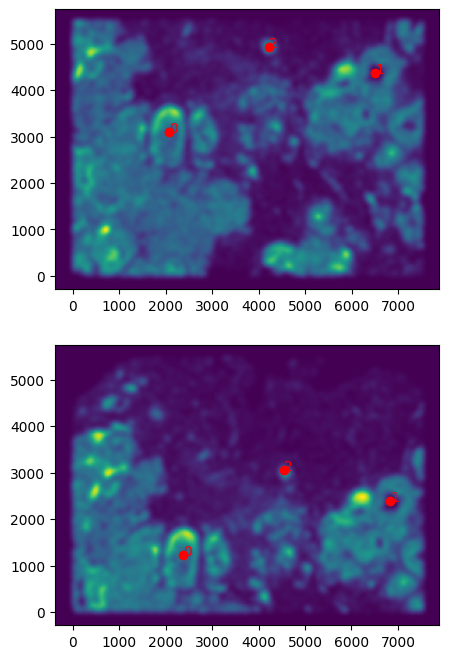
We can now initialize a simple affine alignment from the landmark points.
[16]:
# set device for building tensors
if torch.cuda.is_available():
torch.set_default_device('cuda:0')
else:
torch.set_default_device('cpu')
[17]:
# compute initial affine transformation from points
L,T = STalign.L_T_from_points(pointsI, pointsJ)
A = STalign.to_A(torch.tensor(L),torch.tensor(T))
We can show the results of the simple affine transformation.
[18]:
# compute initial affine transformation from points
AI = STalign.transform_image_source_with_A(A, [YI,XI], I, [YJ,XJ])
#switch tensor from cuda to cpu for plotting with numpy
if AI.is_cuda:
AI = AI.cpu()
fig,ax = plt.subplots(1,2)
ax[0].imshow((AI.permute(1,2,0).squeeze()), extent=extentJ)
ax[1].imshow((J.transpose(1,2,0).squeeze()), extent=extentJ)
ax[0].set_title('source with affine transformation', fontsize=15)
ax[1].set_title('target', fontsize=15)
ax[0].invert_yaxis()
ax[1].invert_yaxis()
/Users/jeanfan/mambaforge/lib/python3.9/site-packages/torch/utils/_device.py:62: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
return func(*args, **kwargs)
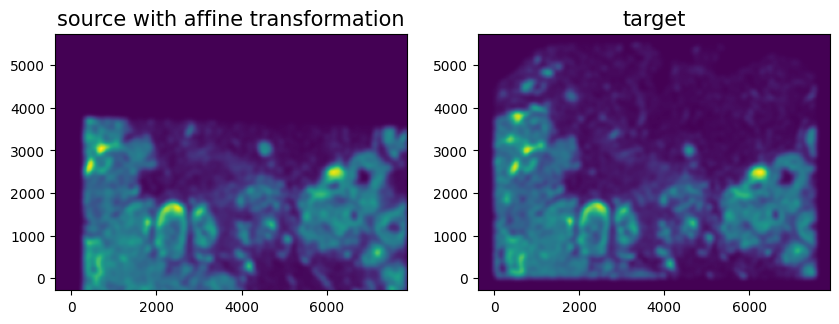
Depending on distortions in the tissue sample (as well as the accuracy of your landmark points), a simple affine alignment may not be sufficient to align the two single-cell spatial transcriptomics datasets. So we will need to perform non-linear local alignments via LDDMM.
There are many parameters that can be tuned for performing this alignment.
[21]:
%%time
# run LDDMM
# specify device (default device for STalign.LDDMM is cpu)
if torch.cuda.is_available():
device = 'cuda:0'
else:
device = 'cpu'
# keep all other parameters default
params = {'L':L,'T':T,
'niter':300,
'pointsI':pointsI,
'pointsJ':pointsJ,
'device':device,
'sigmaM':1.5,
'sigmaB':1.0,
'sigmaA':1.1,
'epV': 100
}
out = STalign.LDDMM([YI,XI],I,[YJ,XJ],J,**params)
CPU times: user 15.5 s, sys: 1.3 s, total: 16.8 s
Wall time: 14.3 s
[22]:
# get necessary output variables
A = out['A']
v = out['v']
xv = out['xv']
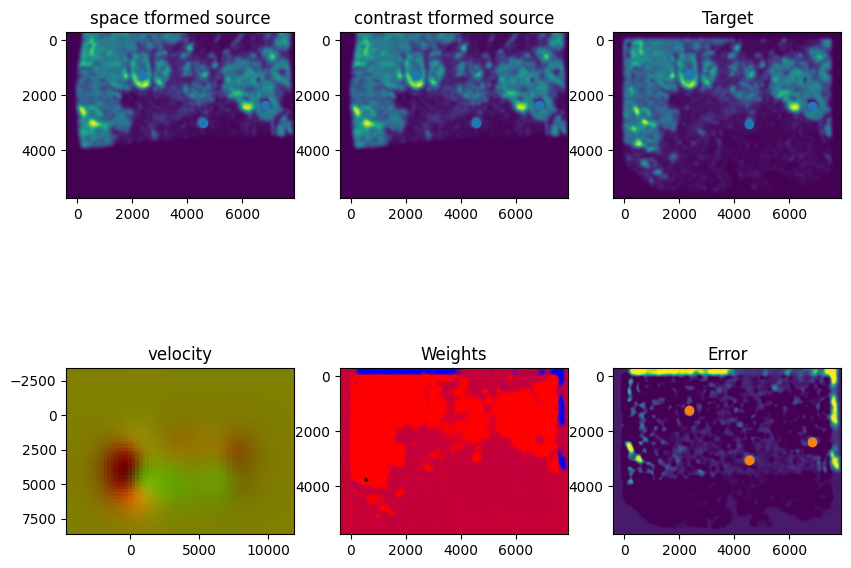
Plots generated throughout the alignment can be used to give you a sense of whether the parameter choices are appropriate and whether your alignment is converging on a solution.
We can also evaluate the resulting alignment by applying the transformation to visualize how our source and target images were deformed to achieve the alignment.
[23]:
# apply transform
phii = STalign.build_transform(xv,v,A,XJ=[YJ,XJ],direction='b')
phiI = STalign.transform_image_source_to_target(xv,v,A,[YI,XI],I,[YJ,XJ])
phipointsI = STalign.transform_points_source_to_target(xv,v,A,pointsI)
#switch tensor from cuda to cpu for plotting with numpy
if phii.is_cuda:
phii = phii.cpu()
if phiI.is_cuda:
phiI = phiI.cpu()
if phipointsI.is_cuda:
phipointsI = phipointsI.cpu()
# plot with grids
fig,ax = plt.subplots()
levels = np.arange(-100000,100000,1000)
ax.contour(XJ,YJ,phii[...,0],colors='r',linestyles='-',levels=levels)
ax.contour(XJ,YJ,phii[...,1],colors='g',linestyles='-',levels=levels)
ax.set_aspect('equal')
ax.set_title('source to target')
ax.imshow(phiI.permute(1,2,0)/torch.max(phiI),extent=extentJ)
ax.scatter(phipointsI[:,1].detach(),phipointsI[:,0].detach(),c="m")
ax.invert_yaxis()
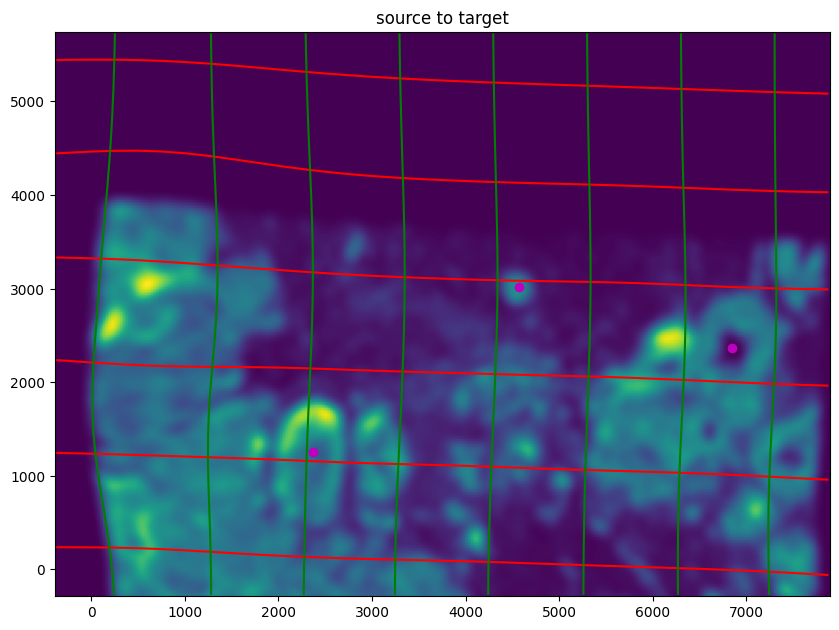
Note that because of our use of LDDMM, the resulting transformation is invertible.
[24]:
# transform is invertible
phi = STalign.build_transform(xv,v,A,XJ=[YI,XI],direction='f')
phiiJ = STalign.transform_image_target_to_source(xv,v,A,[YJ,XJ],J,[YI,XI])
phiipointsJ = STalign.transform_points_target_to_source(xv,v,A,pointsJ)
#switch tensor from cuda to cpu for plotting with numpy
if phi.is_cuda:
phi = phi.cpu()
if phiiJ.is_cuda:
phiiJ = phiiJ.cpu()
if phiipointsJ.is_cuda:
phiipointsJ = phiipointsJ.cpu()
# plot with grids
fig,ax = plt.subplots()
levels = np.arange(-100000,100000,1000)
ax.contour(XI,YI,phi[...,0],colors='r',linestyles='-',levels=levels)
ax.contour(XI,YI,phi[...,1],colors='g',linestyles='-',levels=levels)
ax.set_aspect('equal')
ax.set_title('target to source')
ax.imshow(phiiJ.permute(1,2,0)/torch.max(phiiJ),extent=extentI)
ax.scatter(phiipointsJ[:,1].detach(),phiipointsJ[:,0].detach(),c="m")
ax.invert_yaxis()
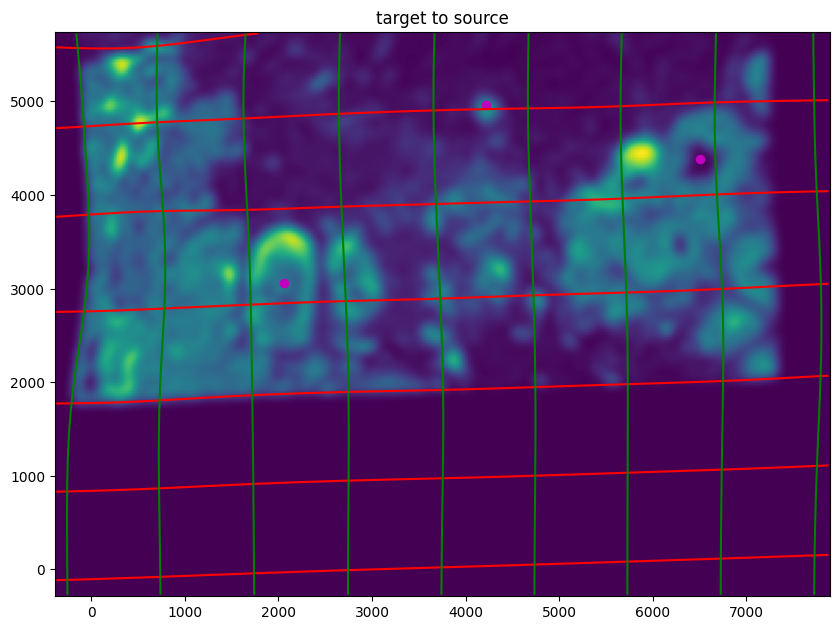
Finally, we can apply our transform to the original sets of single cell centroid positions to achieve their new aligned positions.
[25]:
# apply transform to original points of target to source
tpointsJ = STalign.transform_points_target_to_source(xv,v,A, np.stack([yJ, xJ], 1))
#switch tensor from cuda to cpu for plotting with numpy
if tpointsJ.is_cuda:
tpointsJ = tpointsJ.cpu()
And we can visualize the results.
[26]:
# plot results
fig,ax = plt.subplots()
ax.scatter(xI,yI,s=1,alpha=0.2)
ax.scatter(tpointsJ[:,1],tpointsJ[:,0],s=1,alpha=0.1) # also needs to plot as y,x not x,y
[26]:
<matplotlib.collections.PathCollection at 0x1565500a0>
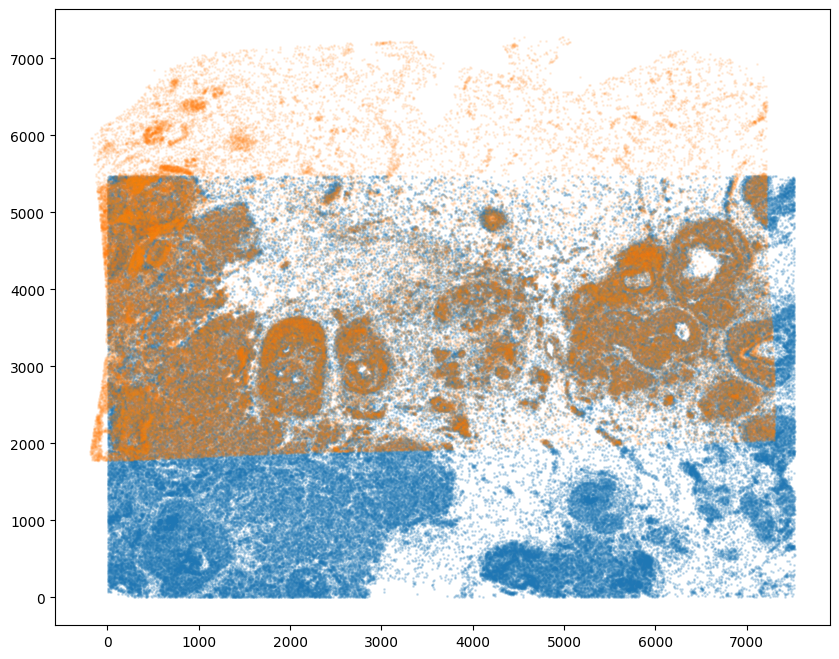
And save the new aligned positions by appending to our original data using numpy with np.hstack
[27]:
# save results by appending
# note results are in y,x coordinates
results = np.hstack((df2, tpointsJ.numpy()))
We will finally create a compressed .csv.gz file to create Xenium_Breast_Cancer_Rep2_STalign_to_Rep1.csv.gz
[ ]:
results.to_csv('../xenium_data/Xenium_Breast_Cancer_Rep2_STalign_to_Rep1.csv.gz',
compression='gzip')
Note that the learned transform can be applied from source to target or target to source.
[28]:
# apply transform to original points of source to target
tpointsI = STalign.transform_points_source_to_target(xv,v,A, np.stack([yI, xI], 1))
#switch tensor from cuda to cpu for plotting with numpy
if tpointsI.is_cuda:
tpointsI = tpointsI.cpu()
# plot results
fig,ax = plt.subplots()
ax.scatter(tpointsI[:,1],tpointsI[:,0],s=1,alpha=0.2) # also needs to plot as y,x not x,y
ax.scatter(xJ,yJ,s=1,alpha=0.2)
[28]:
<matplotlib.collections.PathCollection at 0x155775910>
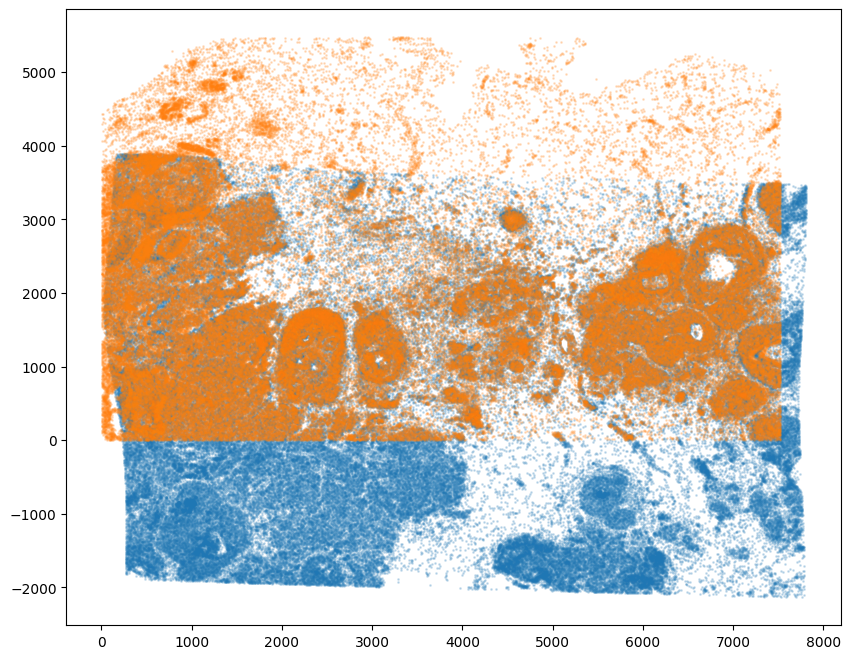
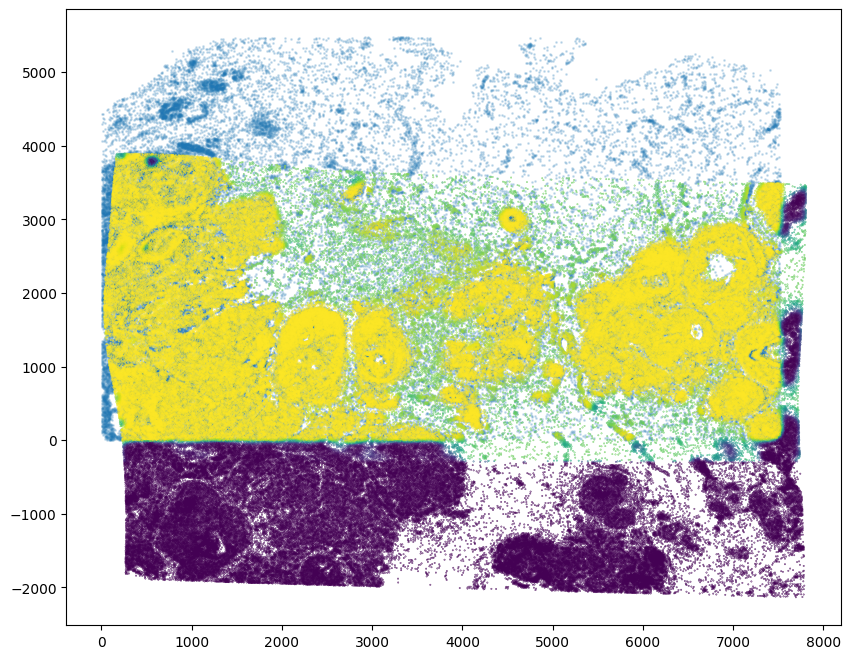
We can also use the matching weights to focus on the tissue region that is overlapping given the partially matching nature of this alignment.
[29]:
# get the weights
WM = out['WM']
# compute weight values for transformed source points from target image pixel locations and weight 2D array (matching)
testM = STalign.interp([YI,XI],WM[None].float(),tpointsI[None].permute(-1,0,1).float())
[30]:
# note some cells were allocated into the artifact component (not matching and so not included, may need to tune sigmaA)
fig,ax = plt.subplots()
ax.scatter(xJ,yJ,s=1,alpha=0.2)
ax.scatter(tpointsI[:,1],tpointsI[:,0],c=testM[0,0],s=0.1,vmin=0,vmax=1, label='WM values')
[30]:
<matplotlib.collections.PathCollection at 0x15571c910>
[31]:
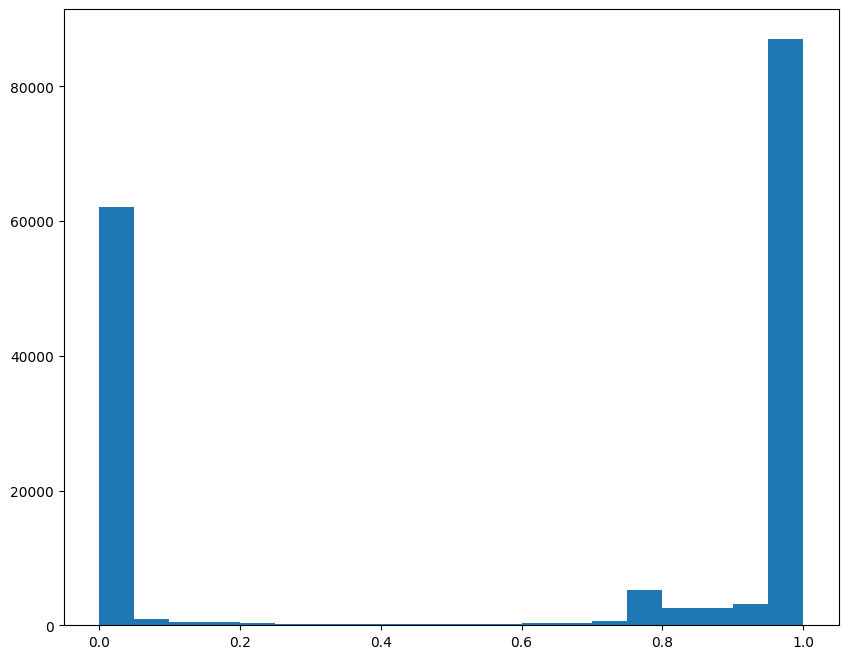
# visualize the distribution to identify reasonable cutoff
fig,ax = plt.subplots()
ax.hist(testM[0,0], bins = 20)
[31]:
(array([62067., 921., 529., 426., 268., 228., 241., 195.,
191., 192., 262., 262., 340., 347., 677., 5234.,
2533., 2621., 3170., 87078.]),
array([0. , 0.04999994, 0.09999988, 0.14999983, 0.19999976,
0.2499997 , 0.29999965, 0.34999958, 0.39999953, 0.44999945,
0.4999994 , 0.54999936, 0.59999931, 0.6499992 , 0.69999915,
0.74999911, 0.79999906, 0.84999901, 0.8999989 , 0.94999886,
0.99999881]),
<BarContainer object of 20 artists>)
[37]:
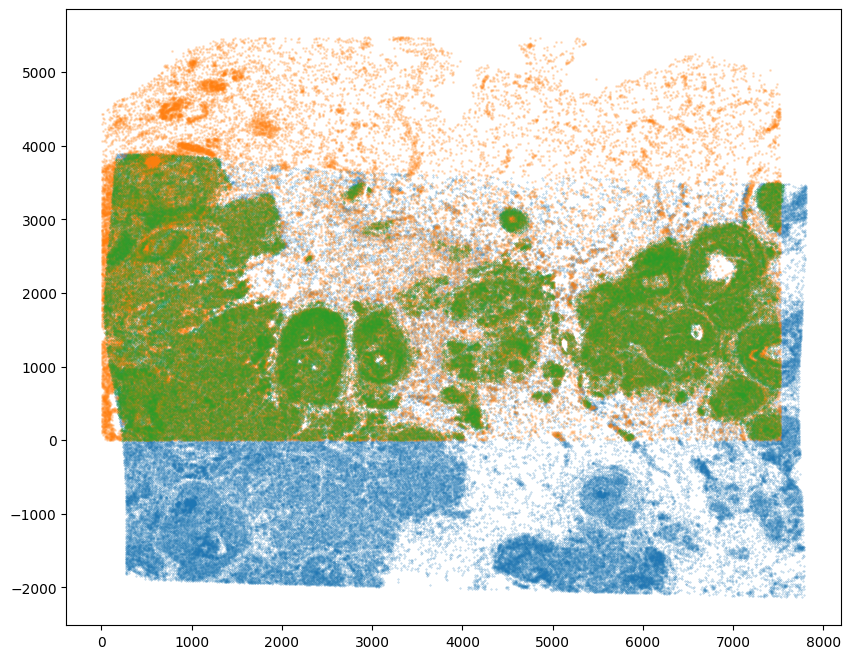
# set a threshold value
WMthresh = 0.9
# plot just the cells that pass filter (overlapping cells)
filtered = testM[0,0] > WMthresh
tpointsI_filtered = tpointsI[filtered,]
fig,ax = plt.subplots()
ax.scatter(tpointsI[:,1],tpointsI[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='original')
ax.scatter(xJ,yJ,s=1,alpha=0.2)
ax.scatter(tpointsI_filtered[:,1],tpointsI_filtered[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='filtered')
/var/folders/h6/yrnr80p14tdb_rr5pln6lg_00000gn/T/ipykernel_55448/834683345.py:9: UserWarning: No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
ax.scatter(tpointsI[:,1],tpointsI[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='original')
/var/folders/h6/yrnr80p14tdb_rr5pln6lg_00000gn/T/ipykernel_55448/834683345.py:11: UserWarning: No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
ax.scatter(tpointsI_filtered[:,1],tpointsI_filtered[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='filtered')
[37]:
<matplotlib.collections.PathCollection at 0x155c5fd90>
[38]:
# choose less stringent threshold value
WMthresh = 0.5
# plot just the cells that pass filter (overlapping cells)
filtered = testM[0,0] > WMthresh
tpointsI_filtered = tpointsI[filtered,]
fig,ax = plt.subplots()
ax.scatter(tpointsI[:,1],tpointsI[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='original')
ax.scatter(xJ,yJ,s=1,alpha=0.2)
ax.scatter(tpointsI_filtered[:,1],tpointsI_filtered[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='filtered')
/var/folders/h6/yrnr80p14tdb_rr5pln6lg_00000gn/T/ipykernel_55448/1163503840.py:9: UserWarning: No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
ax.scatter(tpointsI[:,1],tpointsI[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='original')
/var/folders/h6/yrnr80p14tdb_rr5pln6lg_00000gn/T/ipykernel_55448/1163503840.py:11: UserWarning: No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
ax.scatter(tpointsI_filtered[:,1],tpointsI_filtered[:,0],s=0.1,alpha=0.5,vmin=0,vmax=1, label='filtered')
[38]:
<matplotlib.collections.PathCollection at 0x155c62370>
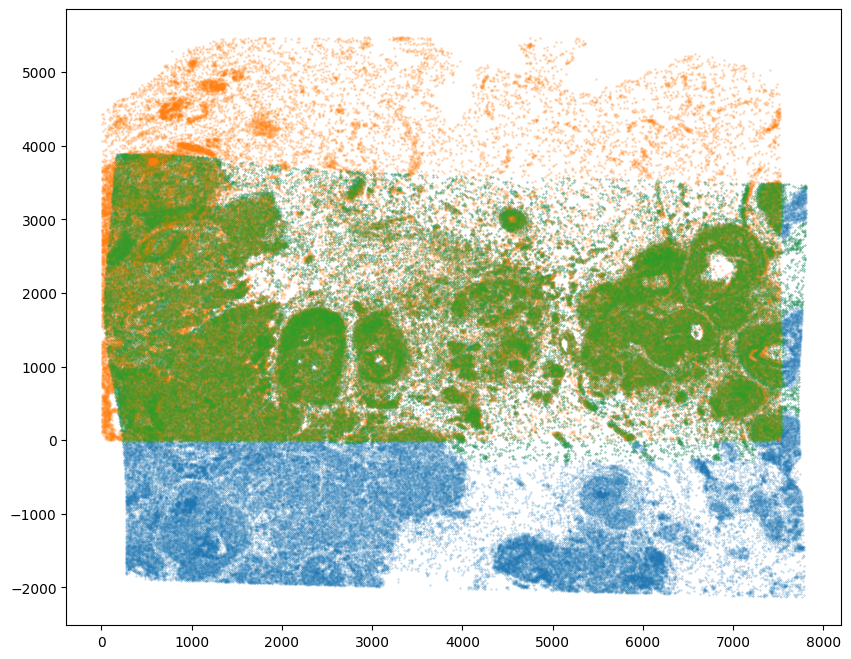
In this manner, we can restrict to just the cells that are matching for downstream analysis.
[ ]:
[ ]: